When I test Kimi, I separate dashboard state, API keys, OpenAI-compatible clients, and regional observation before I decide what the proxy is actually supposed to prove.
Recommendation: I use proxies on Kimi only when they answer a narrow QA question: session stability, route separation, regional observation, or cleaner troubleshooting. I do not use them to imply entitlement, billing success, or policy bypass.
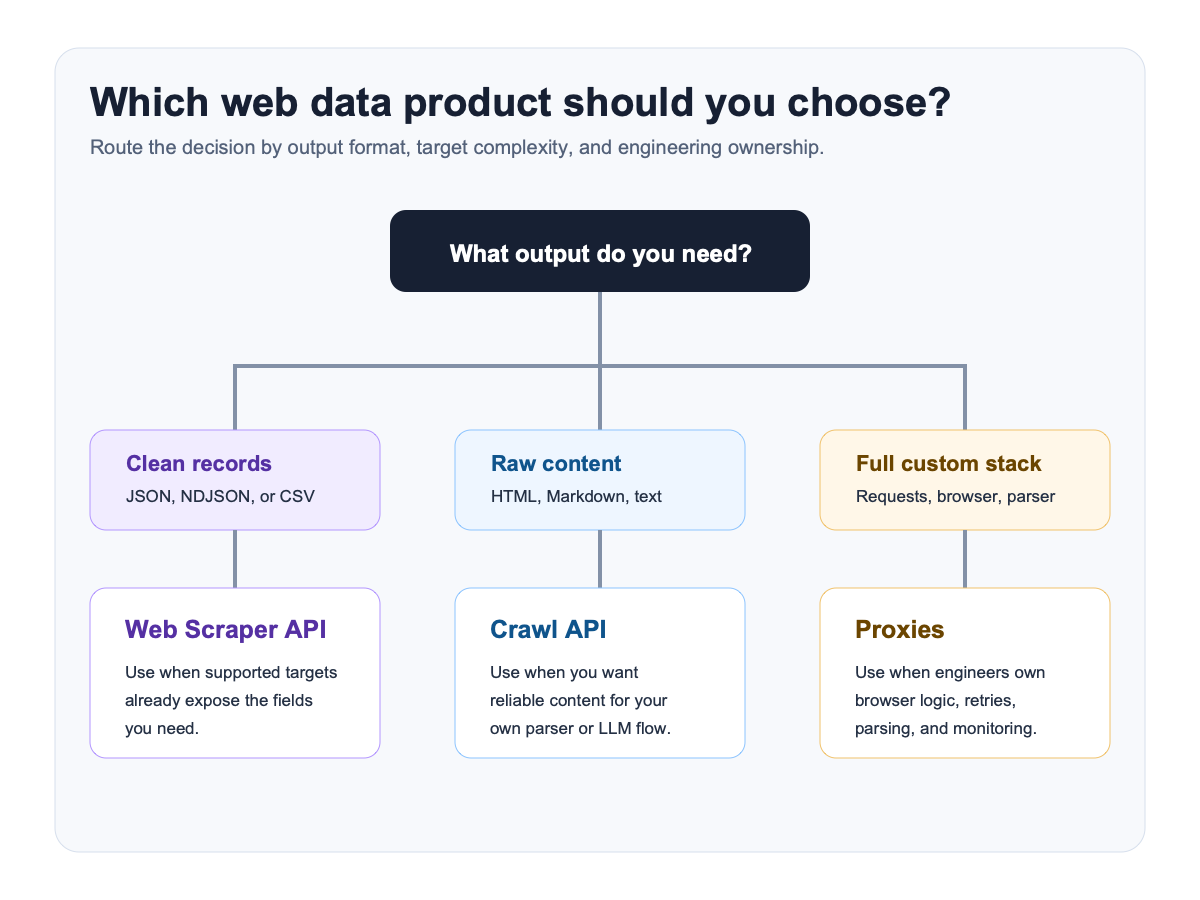
Current official baseline I start from
Kimi Open Platform provides an OpenAI-compatible API surface with MOONSHOT_API_KEY and a Moonshot base URL.
My working read on this surface
Kimi is one of the easiest places for proxy content to become shallow because people talk about it like a generic OpenAI clone. The more useful operator lens is: what is first-party Kimi, what is OpenAI-compatible routing, and what is third-party relay behavior around that API.
What usually changes the result before the proxy does
The common mistake is assuming Kimi behaves like a drop-in OpenAI replacement in every client and every operational flow. Compatibility is useful, but it does not erase account, dashboard, or regional behavior differences.
What breaks in practice first
- The API path works in one OpenAI-compatible client but fails in another because the client assumptions are broader than the platform's compatibility surface.
- Console access, API key management, and relay behavior are blended into one topic, so the operator diagnoses the wrong layer.
- Regional or entitlement differences are read as route failures when the actual issue is platform-side availability or account posture.
What I use the route to observe
- test API or console behavior separately from the rest of your AI stack
- validate OpenAI-compatible base URLs and auth headers cleanly
- keep account, key, and country tests separated so failures are attributable
What I will not promise from a proxy
- They cannot replace model entitlements, platform billing, or official API key issuance.
- They cannot hide SDK incompatibilities or model naming mismatches forever.
- They cannot guarantee the same behavior across all third-party gateways or relay tools.
My observation vs claim-to-avoid matrix
| Scenario | Proxy type I prefer | What I am actually observing | Claim I avoid |
|---|---|---|---|
| Kimi dashboard access | Sticky residential or ISP | Whether the console, key-management page, or model listing behaves consistently | That dashboard behavior predicts API compatibility |
| OpenAI-compatible client path | Stable datacenter or sticky residential | Whether base URL, auth headers, and model naming are configured correctly | That compatibility is automatically complete |
| API key path | Datacenter or stable residential | Whether the native API call works before a relay is added | That a proxy can compensate for wrong client assumptions |
| Regional console observation | Country-specific residential | Whether public docs, dashboards, or onboarding copy vary by market | That a localized page changes entitlement rules |
When I would use a proxy here
- You need to validate dashboard, API, and OpenAI-compatible routing separately.
- You need to test whether regional behavior changes the console or API path you care about.
When I would not buy one yet
- You have not separated console login problems from API base URL and key problems.
My practical QA workflow
- Separate dashboard login, API key management, and OpenAI-compatible client behavior into different tests.
- Verify the native or first-party path first before adding gateways or alternate clients.
- Use a stable route if the workflow involves account-backed consoles or sticky dashboard state.
- Only then compare compatibility, region, and relay-layer differences so you know which layer changed the result.
Provider shortlist I would start with
| Provider | Best fit for this page | Why I would start here |
|---|---|---|
| Bright Data | Best when Kimi spans both developer-console QA and OpenAI-compatible client routing, not just raw API egress. | Best overall for production AI workflows, geo QA, and public-web access layers. |
| Proxy-Seller | Useful when Kimi testing is session stability first and wider web-data tooling is not part of the job. | Strong self-serve option for dedicated or sticky session control at a lower cost. |
| Webshare | Simple lower-friction option for smaller teams testing account separation and gateway routing. | Simple lower-friction option for smaller teams testing account separation and gateway routing. |
| DataImpulse | Useful as a low-cost experiment route when Kimi still needs validation before serious spend. | Budget wildcard for low-cost regional testing and lighter residential experiments. |
What I log before I change anything
- Dashboard or API path
- Client or SDK used
- Base URL and model name
- Account tier or key context
Related AI proxy pages
- AI Proxies
- Best AI Proxy Providers for 2026
- OpenRouter Proxies for 2026
- Kimi OAuth Proxies for 2026
- GLM Proxies for 2026
- Z.AI Proxies for 2026
FAQ
Do I actually need a proxy for Kimi?
Only when you need network separation, country-specific QA, gateway routing, or a more stable browser or CLI session than your default path provides.
Which proxy type is the safest default for Kimi?
For account or CLI sessions, sticky ISP or static residential is usually the safest default. For broader country QA, rotating residential is more flexible.
What cannot be fixed by a proxy on Kimi?
Expired credentials, unsupported countries, missing entitlements, bad project settings, and broken gateway logic are all outside the proxy's control.
Sources checked
- https://platform.kimi.ai/docs/api/overview
- https://platform.kimi.ai/docs/guide/migrating-from-openai-to-kimi
- https://brightdata.com/proxy-types
- https://docs.z.ai/guides/develop/openai/python
Final verdict
I use proxies on Kimi once the underlying surface is clear and the observation goal is narrow. The route can help me isolate state, compare markets, and keep QA repeatable, but it is not a substitute for real entitlements, clean auth, or correct project setup.






