Are there any difficulties you're having when scraping Cloudflare-protected websites? The solution to ending the struggle is in this article. With Cloudscraper in your toolbox, you won't need to worry about being blocked or banned.

You would agree with me that Cloudflare does an excellent job of protecting websites from cyberattacks if you have ever been to a website that is under its protection. Cloudflare has become one of the top web security solutions for defense against bots and unwanted traffic as fraudsters search for new methods to take advantage of people and businesses.
With web scrapers, this WAF can be difficult, though. You might come across certain websites that use Cloudflare protections, which makes them much harder to scrape when searching the internet for relevant information. So, whatever your motives are, you stand a chance of still being blocked.
Nevertheless, there is a way around it. With Cloudscraper, you can bypass Cloudflare’s anti-bot protection to get the data you need. Besides, in today’s data-driven world, web scraping has become an essential tool for researchers, data scientists, and businesses. As such, Cloudscraper is a useful Python module designed specifically to bypass Cloudflare’s anti-bot pages. It is also known as “I'm Under Attack Mode” (IUAM).
This article will explain Cloudscraper in detail and show you how to take advantage of it whenever you need to scrape a website that is Cloudflare-protected. Let's begin right away.
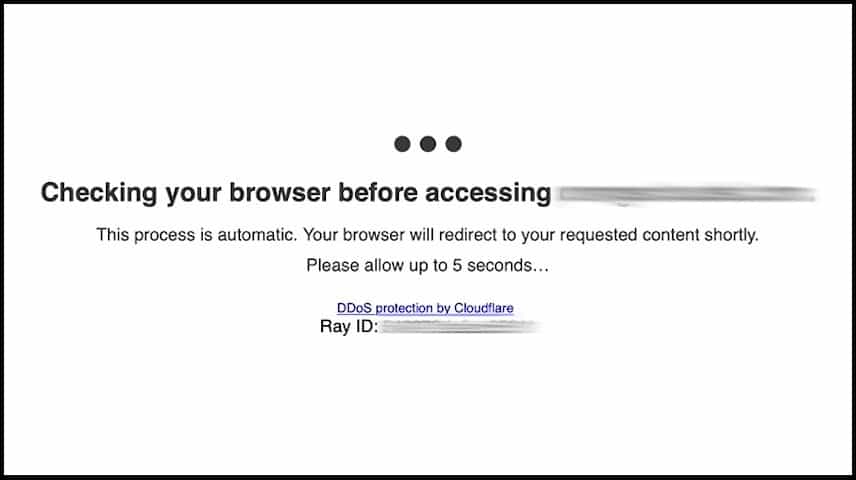
Cloudflare Protection Message
Before we move forward to understand what Cloudscraper is, we thought it would be helpful to know one of the common messages you would see when you visit a web page protected by Cloudflare.
What is Cloudscraper?
Cloudscraper is a straightforward Python program that can bypass Cloudflare's “I'm Under Attack Mode” (IUAM) anti-bot page.
In other words, Python requests serve as the foundation for this Python module. Hence, it is built on Python requests. You can use it to get over Cloudflare's anti-bot security measures so you can scrape information from websites that have their content deployed on Cloudflare's CDN.
The anti-bot page from Cloudflare presently only verifies if JavaScript is supported by the client. To verify whether a request is coming from a real user, a scraper, or a bot, Cloudflare employs a variety of browser fingerprinting techniques and checks. Because of this, Cloudscraper pretends to be a legitimate web browser in an effort to bypass Cloudflare's JavaScript and browser fingerprinting restrictions. It achieves this without having to directly deobfuscate and parse Cloudflare's JavaScript challenges by optimizing browser headers and using a JavaScript engine or interpreter to resolve JavaScript issues. Because Cloudflare's web page protection is always evolving and hardening, the JavaScript engine and interpreter are essential.
Note that any script using Cloudscraper will sleep for approximately 5 seconds on the first visit to any site with Cloudflare anti-bots enabled. However, there would be no delay after the first request. The most recent version of Cloudscraper was launched on April 26, 2023, at the time this article was being written.
The Installation of Cloudscraper
The installation process for Cloudscraper is very straightforward. You just need to run the code below using pip.
pip install cloudscraper
The PyPI package can be located at https://pypi.python.org/pypi/cloudscraper/. Hence, as soon as Cloudscraper is installed, you can integrate it into your scrapers.
Alternatively, to install Cloudscraper, you can clone the repository and run the code below:
python setup.py install
This would install the Python dependencies automatically. Except for js2py, which is included in the prerequisites as the default, the only things you need to install yourself are the javascript interpreters and/or engines you choose to use. It would install Python 3 and later, requests >= 2.9.2, and requests_toolbelt >= 0.9.1 requirements. Remember that some systems already have it installed. Make sure to install all required libraries after you have installed these.
The following JavaScript interpreters and engines are supported by Cloudscraper, according the project documentation:
- ChakraCore:Library binaries can also be seen here.
- js2py:>=0.67
- native: A self made native python solver (Default)
- js
- V8:This uses Sony's v8eval() python module.
How to Use Cloudscraper

As we discussed in the last section, Python requests are the foundation upon which CloudScraper is based. As such, with the exception of not making requests calls, cloudScraper functions exactly like a Requests Session object. But it handles Cloudflare's challenges in the background.
Therefore, using Cloudscraper will be simple if you are familiar with this HTTP library. Requests to websites secured by the Cloudflare anti-bot will be handled automatically from this session object. Websites without Cloudflare will receive the usual approach.
The same principles apply when using Cloudscraper as when using Requests. So, instead of using requests.get() or requests.post(), you can use scraper.get() or scraper.post(). Here is an example of this:
import cloudscraper
## Create CloudScraper Instance
scraper = cloudscraper.create_scraper()
## Make Request
response = scraper.get("http://exampleofyourtargetwebsite.com")
So let me remind you that the first time you visit a Cloudflare-protected website, CloudScraper will sleep for roughly five seconds to give it time to get past the Cloudflare challenge. Cloudscraper will make use of the aforementioned session cookies on all subsequent requests to avoid setting off the Cloudflare challenge after it has successfully completed the Cloudflare challenge and earned a valid Cloudflare session.
However, if you run Cloudscraper on a website without Cloudflare protection activated, Cloudscraper will recognize this and won't wait the required five seconds to resolve the Cloudflare challenge. Because Cloudscraper only activates itself when necessary, using it across all of your target web sites is a smart idea.
Using Proxies with CloudScraper

To even further strengthen your web scraping, you can use proxies alongside Cloudscraper. You can do this just the way you would with Python requests. You would use the proxies attribute when making a get() or post() request. Below is the code to describe it:
import cloudscraper
## This Would Create CloudScraper Instance
scraper = cloudscraper.create_scraper()
## These are the Proxy Details
proxies = {
'http': 'http://proxy.example.com:8080',
'https': 'http://proxy.example.com:8081',
}
## Here You can Make Request
response = scraper.get("http://exampleofyourtargetwebsite.com", proxies=proxies)
The Python requests package enables you to distribute your requests across numerous IP addresses, making it more difficult for websites to identify and ban your web scrapers. All request methods that Python Requests offers are successfully handled by the method. They are GET, POST, PUT, DELETE, PATCH, and HEAD, among others.
Using CAPTCHA Solvers with CloudScraper

We would also examine how to use Cloudscraper alongside a CAPTCHA solver. By presenting CAPTCHA challenges, Cloudflare is able to identify and stop bots and scrapers. Interestingly, Cloudscraper also offers integrated plug-ins for third-party CAPTCHA solvers, should you need them, to enable you to bypass Cloudflare anti-bot security on a website.
Check out the documentation here for the most recent list of CAPTCHA solvers that are supported.
Using these CAPTCHA solvers with Cloudscraper is quite simple and easy. Below is an example of how to integrate Capsolver:
scraper = cloudscraper.create_scraper(
captcha={
'provider': 'capsolver',
'api_key': 'your_captchaai_api_key'
}
)
## Make Request
response = scraper.get("http://exampleofyourtargetwebsite.com")
The third-party CAPTCHA is used by your Cloudscraper object to add it as a property or is supplied as an argument to the create_scraper(), get_tokens(), and get_cookie_string() functions.
You should visit the documentation here to see the required parameters for all the available integrative CAPTCHA solvers.
How To Changing Cloudscraper's Browser Profiles and User-Agents.

You can instruct CloudScraper to simulate a specific browser and device while accessing websites protected by Cloudflare. When building your scraper, you should take advantage of the browser attribute in order to achieve this. The code in the example below is meant to establish a Cloudscraper session that pretends as a Windows machine, running on a desktop, and using the Chrome browser.
import cloudscraper
## Create CloudScraper Instance -> Chrome browser // Windows OS // Desktop
scraper = cloudscraper.create_scraper(
browser={
'browser': 'chrome',
'platform': 'windows',
'desktop': True,
'mobile': False,
}
)
## Make Request
response = scraper.get("http://exampleofyourtargetwebsite.com")
On the other hand, you can set up your Cloudscraper session to appear to be an Android phone that is running the Chrome browser:
import cloudscraper
## This would Create CloudScraper Instance -> Chrome browser // Windows OS // Desktop
scraper = cloudscraper.create_scraper(
browser={
'browser': 'chrome',
'platform': 'android',
'desktop': False,
'mobile': True,
}
)
## Make Request
response = scraper.get("http://exampleofyourtargetwebsite.com")
Setting Custom User-Agents
With the code below, you can influence how and which User-Agent is “randomly” chosen:
import cloudscraper
## Create CloudScraper Instance -> Custom User-Agent
scraper = cloudscraper.create_scraper(
browser={
'custom': 'ScraperBot/1.0',
}
)
## Make Request
response = scraper.get("http://exampleofyourtargetwebsite.com")
By specifying a custom value, CloudScraper will look in browsers.json for the user-agent string. The other headers and ciphers will be set to match this user-agent setting if the custom user-agent you supplied matches a known device, OS, or browser combination.
The user-agent will set a generic set of headers and ciphers if it doesn't match any known device, OS, or browser combinations in the browsers.json file.
In order to avoid Cloudflare marking you as a bot, you must use the same user-agent string while requesting tokens and making requests with those tokens. A pair of cookie, user_agent_string is what the two integration functions return. This means that whatever script, tool, or service you are sending the tokens to, such as curl or a specialist scraping tool, must use the provided user-agent when it makes HTTP requests. You must pass that user-agent to the script, tool, or service.
How To Bypass Cloudflare Using Cloudscraper

When it comes to bypassing Cloudflare’s anti-bot and DDoS protection with Cloudscraper, a lot of work goes into it. However, you shouldn't really be concerned with what goes on behind the scenes. Calling the scraper function and waiting to collect the data you need should be your only concerns. Here are some instructions on how to go about it.
1. Import Cloudscraper and all required dependencies, same as we did before. Here, we are taking factoring BeautifulSoup.
from bs4 import BeautifulSoup import cloudscraper
2. Create a Cloudscraper instance after that, and specify your desired website.
scraper = cloudscraper.create_scraper() url = "http://exampleofyourtargetwebsite.com"
Having created the Cloudscraper instance and defined your target website, it is time to access the website to retrieve its data.
info = scraper.get(url) print(info.status_code) soup = BeautifulSoup(info.text, "html.parser") print(soup.find(class_ = "definetheclass").get_text())
When combined, the code should look like this:
from bs4 import BeautifulSoup import cloudscraper scraper = cloudscraper.create_scraper() url = "http://exampleofyourtargetwebsite.com" info = scraper.get(url) print(info.status_code) soup = BeautifulSoup(info.text, "html.parser") print(soup.find(class_ = "classgoeshere").get_text())
With this, you've successfully bypassed Cloudflare's DDoS protection.
Cloudscraper and Cloudflare Newer Versions
One thing you need to know about Cloudflare is that it often changes its bot protection tactics. So let's pretend for a moment that you want to scrape data from a web page that is protected by a more recent version of Cloudflare. The website would automatically lead you to the Cloudflare waiting area if you accessed it using a browser. It will determine if your connection is secure there.
Cloudflare would accept your connection and direct you to the original home page because you are sending the request from a legitimate browser. However, if you use the following code to access the same page using Cloudscraper,
import cloudscraper
url = " http://exampleofyourtargetwebsite.com"
scraper = cloudscraper.create_scraper()
info = scraper.get(url)
print("the status code is ", info.status_code)
print(info.text)
The one thing you would notice is that you would see an error message like this:
cloudscraper.exceptions.CloudflareChallengeError: Detected a Cloudflare version 2 challenge, This feature is not available in the opensource (free) version.
The error message that had been shown above implies that Cloudscraper has a premium version that would function. Then, how can I resolve this difficulty? You may ask. Since Cloudflare uses a variety of continuously updated strategies to facilitate bot detection and blocking, one way to address this is by mimicking real user behaviour. Additionally, you can accomplish it by using valid and appropriate headers for HTTP requests combined with headless browsers like Selenium or Puppeteer. Keep in mind, nevertheless, that these methods have their drawbacks and occasionally fail.
Reasons You Need a Cloudscraper
Back in the day, marketers encountered technical challenges when attempting to pull massive volumes of data from dynamic web pages. With technologies like Cloud Scraper, web data extraction has become more streamlined. You can choose to use your own machine to extract data from other websites and analyze it.
However, here are some of the reasons why you need Cloudscraper in order to scrape websites that are DDoS- and anti-bot-protected by Cloudflare.
-
Capturing dynamic content
To collect dynamic content that other scraping tools might not be able to access, Cloudscraper combines JavaScript rendering and browser automation. Hence, when you use Cloudscraper, you are sure to scrape any dynamic content you need.
-
Privacy
Many individuals give up trying to scrape content from some websites that use the Cloudflare CDN because of how difficult the protection provided by Cloudflare is to bypass. Your anonymity and privacy are guaranteed with Cloudscraper, however. Your identity is protected by Cloudscraper, which also hides your IP address and device details.
-
Avoid Data Leak
Cloudscraper is the program you need if you want to scrape a website while using Cloudflare protection to prevent data leaks. To achieve this, you can modify the user agent and browser profile. No matter what browser or device you are using, doing this has an extremely low likelihood of causing your original data to leak.
-
You be Integrated with Third Party Programs.
When scraping a protected website, Cloudscraper's flexibility allows you to integrate additional programs to improve its performance. Several third-party CAPTCHA solvers and proxies are available for integration. With these technologies and Cloudscraper working together, you can accomplish so much.
-
Easy to use
When configured properly, Cloudscraper can be simple to use, especially for individuals who are no strangers to Python programming. Its straightforward API is comparable to that of Python's Requests module.
Limitations of Cloudscraper
While Cloudscraper does a great job, it has a little drawback of which we wish you would take note. It does really have many vulnerabilities, but these few are worth taking note of:
-
No Total Anonymity
CloudScraper isn't an all-encompassing solution for scraping, as Cloudflare also employs other scraper detection methods like IP address profiling to find scrapers. With Cloudscraper, we can't guarantee your complete anonymity. However, you need to use high-quality proxies and tailor your requests to make them appear as though they are originating from real people in order to scrape Cloudflare-protected websites with any form of suspicion.
-
It has Bugs
Cloudscraper is a Python library that is frequently employed in automation and bot applications. It features a constructed file, a permissive license, and medium support. However, Cloudscraper had over 14 bugs at the time this article was being written. We know and believe that its developers are attempting to address it.
-
Performance
Cloudscraper can be slower than other scraping solutions that solely use HTTP requests since it combines JavaScript rendering, browser automation, and HTTP request replay. This can make it inappropriate for use cases requiring swift responses or for scraping massive amounts of data.
-
Complexity
Since Cloudscraper uses JavaScript rendering and browser automation, it can be more difficult to set up and operate than other scraping solutions. Users who are unfamiliar with web scraping or have little programming skills may find it difficult as a result.
-
Maintenance
It may be necessary to update Cloudscraper's code to keep up with Cloudflare's frequent upgrades to its anti-bot defense techniques. As a result, Cloudscraper might not always function properly with the most recent version of Cloudflare's security and might need upkeep.
FAQs
Q. Is Cloudscraper a Reliable Too for Bypassing Cloudflare?
Actually, Cloudscraper does a decent job of bypassing Cloudflare's defenses. To achieve the best and most rewarding web scraping experience, it is suggested that you combine it with reliable proxies and CAPTCHA solvers. The integration with these third-party applications is quite straightforward and simple to carry out.
Q. What Is The Meaning Of a 403 Response While Using Cloudscraper?
The HTTP response status code 403 Forbidden denotes that the server understands the request but chooses not to approve it. If you did not have the authorization, however, we advise you to first see if the URL you are submitting the request to requires any kind of authorization. On your second or third attempt, you do, however, receive an answer. Some servers take a few seconds to respond, which means the browser must wait for about 5 seconds before sending the response on these servers.
Q. Does Cloudscraper Work With All Versions of Cloudflare?
No, Cloudscraper isn't compatible with all Cloudflare versions, particularly the more recent ones. Therefore, it is a good idea to be aware of the Cloudflare version your target website is working with and how to approach it. There are further methods you can use with Cloudscraper to get around these more recent Cloudflare versions. One of them is mimicking real user behavior.
Conclusion
You have it. By now, you should be able to understand what Cloudscraper does and how to use it. We've also demonstrated how to use CloudScraper to scrape Cloudflare-protected webpages. We've seen that using Cloudscraper in Python to bypass older Cloudflare versions is particularly helpful; however, other libraries can be engaged in order to get around its more recent versions. In light of this, we hope that this article truly orients you toward Cloudscraper.





