In this tutorial, you will dig into Rust web scraping. Specifically, you will learn:
- Why Rust is a great language for scraping the Web efficiently.
- What the best scraping libraries in Rust are.
- How to build a Rust scraper from scratch.
Let’s dive in!
Can You Perform Web Scraping with Rust?
TL;DR: Yes, you can! And Rust is an efficient choice too!
Rust is a statically typed programming language known for its focus on security, performance, and concurrency. In recent years, it has gained popularity for its high efficiency. That makes it an excellent choice for a variety of applications, including web scraping.
In detail, Rust offers useful features for online data scraping tasks. For example, its reliable concurrency model allows multiple web requests to be executed simultaneously. This is why Rust is a versatile language for efficiently scraping large volumes of data from multiple websites.
On top of that, the Rust ecosystem includes HTTP client and HTML parsing libraries that simplify web page retrieval and data extraction. Let's explore some of the most popular ones!
Best Rust Web Scraping Libraries
Here is a list of some of the best web scraping libraries for Rust:
- reqwest: A powerful HTTP client library for Rust. It provides an easy and efficient API to make HTTP requests. Thanks to it, you can download web pages, handle cookies, and customize headers, making it an essential library for fetching web content in your scraping project.
- scraper: A Rust library that simplifies HTML parsing and data extraction. It enables you to traverse and manipulate HTML documents via CSS selectors through built-in methods.
- rust-headless-chrome: A Rust library that exposes a high-level API for controlling headless instances of Chrome via the DevTools protocol. You can think of it as the Rust equivalent of Puppeteer. This is an indispensable tool for tackling scraping tasks involving dynamic pages that require JavaScript rendering or browser automation.
Prerequisites
To follow this web scraping Rust tutorial, you need to have Rust installed on your computer. Launch the command below in your terminal to verify that:
rustc --version
If the result is as follows, you are ready to go:
rustc 1.73.0 (cc66ad468 2023-10-03)
If it ends in an error, you need to install Rust. Download the installer from the official site and follow the instructions. This will set up:
You know need an IDE to code in Rust. Visual Studio Code with the rust-analyzer extension installed is a free and reliable solution.
Build a Web Scraper in Rust
In this step-by-step section, you will see how to build a Rust web scraper. You will code an automated script that can automatically retrieve data from the Quotes scraping sandbox. The goal of the Rust web scraping process will be to:
- Select the quote HTML elements from the page.
- Extract data from them.
- Convert the collected data to an easy-to-explore format, such as CSV.
As of this writing, this is what the target site looks like:

Follow the instructions below and learn how to perform web scraping in Rust!
Step 1: Set up a project in Rust
Time to initialize your Rust web scraper project. Open the terminal in the folder you want to place your project in and run the cargo command below:
cargo new rust_web_scraper
A rust_web_scraper directory will appear. Open it and you will see:
- toml: The manifest file that contains the project’s dependencies.
- src/: The folder containing the Rust files.
Open the rust_web_scraper folder in your IDE. You will notice that the main.rs file inside the src directory contains:
fn main() {
println!("Hello, world!");
}
This is what the simplest Rust script looks like. The main() function represents the entry point of any Rust application.
Perfect, verify that your script works!
In the terminal of your IDE, execute the command below to compile your Rust app:
cargo build
This should create a binary file in the target folder.
You can now run the binary executable with:
cargo run
If everything goes as expected, it should print in the terminal:
Hello, World!
Great, you now have a working Rust project! Right now, your scraper simply prints “Hello, World!” but it will soon contain some scraping logic.
Step 2: Install the project's dependencies
Before installing any package, you need to figure out which Rust web scraping libraries best suit your goals. To do that, open the target site in your browser. Right-click and select the “Inspect” option to open the DevTools. Then, reach the “Network” tab, reload the page, and take a look at the “Fetch/XHR” section.
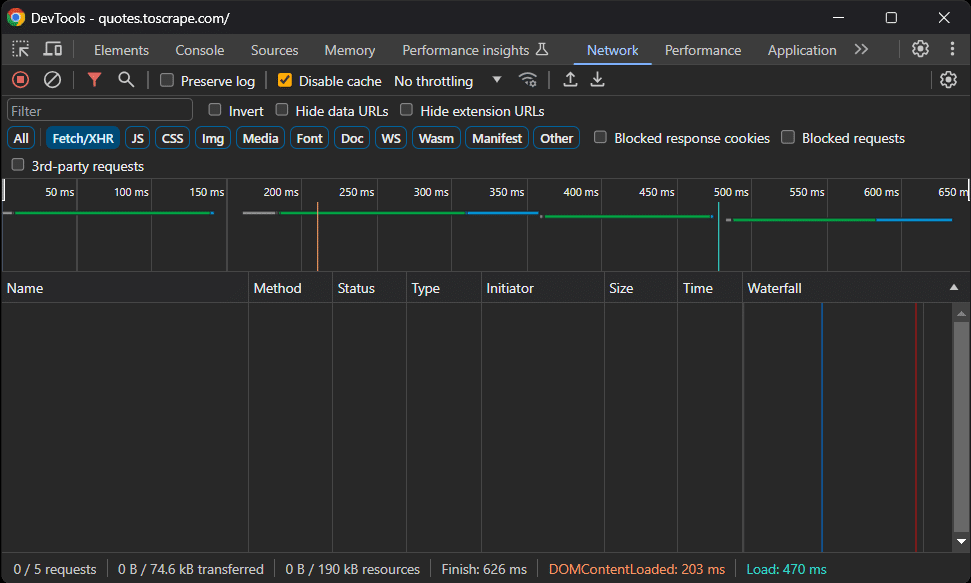
As you can see, the web page does not perform any AJAX requests. In other words, it does not retrieve data dynamically on the client. Therefore, it is a static page whose HTML content already contains all the data.
As a result, you do not need a library with headless browser capabilities to perform web scraping on it. You can still use Headless Chrome, but this would only introduce a performance overhead. That is why you should go for:
- reqwest: As the HTTP client to retrieve the HTML documents associated with the target pages.
- scraper: As the HTML parser to parse the HTML content and retrieve data from it.
Add reqwest and scraper to your project's dependencies with:
cargo add scraper reqwest --features "reqwest/blocking"
The command will update the Cargo.toml file accordingly.
Well done! You now have everything required to perform data scraping in Rust!
Step 3: Download the target page
Use reqwest's blocking HTTP client to download the HTML document of the target page:
let response = reqwest::blocking::get("https://quotes.toscrape.com/");
let html = response.unwrap().text().unwrap();
Behind the scenes, get() performs a synchronous HTTP GET request to the URL passed as a parameter. Script execution will be stopped until the server responds.
To extract the raw HTML as a string from the response, you need to call unwrap() twice to:
- Unwrap the Result object stored in the response variable. If the request is successful, you will get the response returned by the server. Otherwise, that will cause a Rust panic.
- Unwrap its text content to access the HTML content.
Step 4: Parse the HTML document
Now that you have the HTML content of the target page stored in a string, you can feed it to scraper:
let document = scraper::Html::parse_document(&html)
The document object exposes the data extraction API exposed by the HTML parser.
Your main.rs file should now look like as follows:
fn main() {
// download the HTML document associated with the target page
let response = reqwest::blocking::get("https://quotes.toscrape.com/");
// extract the raw HTML from the response
let html = response.unwrap().text().unwrap();
// parse the HTML content
let document = scraper::Html::parse_document(&html);
// scraping logic...
}
Step 5: Inspect the page content
Time to analyze the structure of the target URL to devise an effective data retrieval strategy.
Open Quotes To Scrape in your browser. You will see a list of quotes. Right-click on one of these elements and select “Inspect.” The DevTools of your browser will open as below:
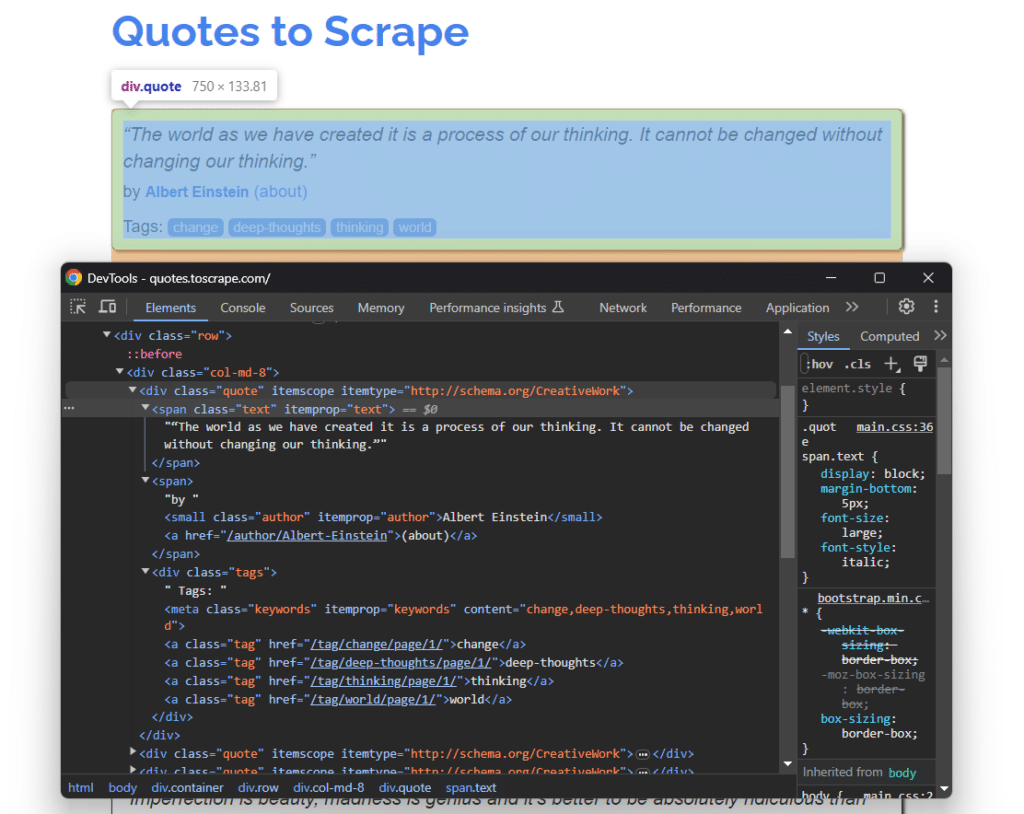
There, you can notice that each quote card is a .quote HTML node that contains:
- A .text element storing the quote text.
- A .author element containing the name of the author.
- Many .tag elements, each displaying a single tag.
The above notes contain all the CSS selectors required to select the desired DOM elements. Now you need to use them in your code to perform Rust web scraping!
Step 6: Implement data scraping
Before getting started, you need a custom data structure where to store your scraped data. Add the following lines on top of your main.rs file to define a new struct:
struct Quote {
quote: Option<String>,
author: Option<String>,
tags: Vec<String>,
}
Since the page contains several quotes, instantiate a Vec of Quote objects in main():
let mut quotes: Vec<Quote> = Vec::new();
At the end of the script, quotes will contain all your scraped data.
See how to populate that array!
Define a CSS Selector object in scraper as follows:
let html_quote_selector = scraper::Selector::parse(".quote").unwrap();
Next, use the select() method to apply on the page and retrieve the desired HTML elements:
let html_quotes = document.select(&html_quote_selector);
You can now iterate over each quote element and extract the data of interest from it with:
for html_quote in html_quotes {
let quote_selector = scraper::Selector::parse(".text").unwrap();
let quote = html_quote
.select("e_selector)
.next()
.map(|element| element.text().collect::<String>());
let author_selector = scraper::Selector::parse(".author").unwrap();
let author = html_quote
.select(&author_selector)
.next()
.map(|element| element.text().collect::<String>());
let tags_selector = scraper::Selector::parse(".tag").unwrap();
let tags = html_quote
.select(&tags_selector)
.map(|element| element.text().collect::<String>())
.collect();
// create a new quote object with the scraped data
// and store it in the list
let quote_obj = Quote {
quote,
author,
tags,
};
quotes.push(quote_obj);
}
The first few lines apply the same approach seen above. They define a CSS selector object and apply it on the quote HTML element. Since select() returns several elements, you can use next() to get the first one. Then, the text() method gives you access to its text content.
Once you get the scraping data, it only remains to populate a new Quote object and add it to the array.
Fantastic! You just learned how to perform web scraping in Rust!
Step 7: Add crawling logic
You just extracted data from a single page, but do not forget that the list of quotes consists of multiple pages. In particular, each page has a “Next →” button with a link to the following page:
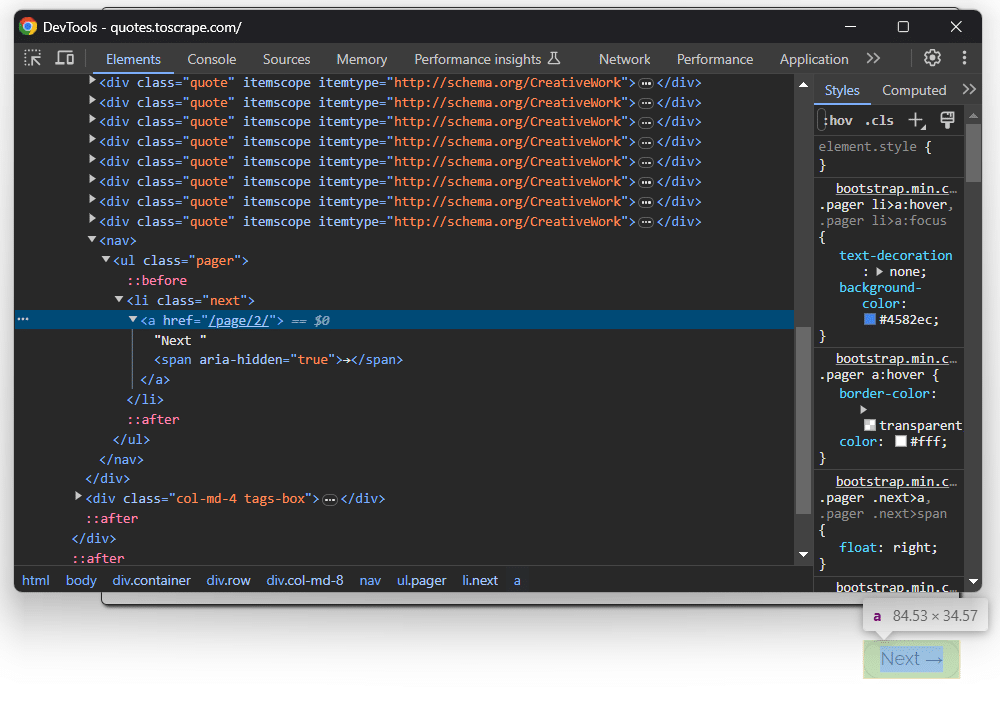
This is true for all pages except the last one:
To perform web crawling and scrape data from each page, you need to:
- Scrape a page.
- Look if the “Next →” element is present on the page.
- If so, follow its URL and repeat the cycle for a new page. Otherwise, stop the crawling logic.
Implement the above algorithm in Rust as below:
// the URL of the first page to scrape
let mut url = "https://quotes.toscrape.com/".to_owned();
loop {
// download the HTML document associated with the target page
let response = reqwest::blocking::get(url);
// parsing and scraping logic...
// select the "Next ->" element
let next_page_element_selector = scraper::Selector::parse(".next").unwrap();
let next_page_element = document.select(&next_page_element_selector).next();
// if this is not the last page
if next_page_element.is_some() {
// retrieve the relative URL to the next page
let next_page_link_selector = scraper::Selector::parse("a").unwrap();
let partial_url = next_page_element
.unwrap()
.select(&next_page_link_selector)
.next()
.and_then(|a| a.value().attr("href"))
.map(str::to_owned)
.unwrap();
// the next page to scrape
url = format!("https://quotes.toscrape.com{partial_url}");
} else {
break;
}
}
Wonderful! The Rust data scraping logic is complete!
Step 8: Export the extracted data to CSV
The scraped data is now stored in Rust objects. You need to convert it to a different forma to make it easier to read and use by other members of your team. See how to export the collected data to a CSV file.
You could create a CSV file and populate with vanilla Rust, but the CSV library makes everything easier. Install it with:
cargo add csv
You can now convert quotes to a CSV file with just a few lines of code:
// initialize the CSV output file
let path = std::path::Path::new("quotes.csv");
let mut writer = csv::Writer::from_path(path).unwrap();
// append the header to the CSV
writer.write_record(&["quote", "author", "tags"]).unwrap();
// populate the CSV file
for quote_obj in quotes {
// if the "quote" and "author" fields are not None
if let (Some(quote), Some(author)) = (quote_obj.quote, quote_obj.author) {
let tags = quote_obj.tags.join("; ");
writer.write_record(&[quote, author, tags]).unwrap();
}
}
// free up the writer resources
writer.flush().unwrap();
The above snippet initializes a CSV file with the header row. Then, it iterates over the array of quotes, converts each element to records in CSV formats, and appends it to the output file.
Step 9: Put it all together
Here is the complete code of your Rust scraper:
// define a custom data structure
// where to store the scraped data
struct Quote {
quote: Option<String>,
author: Option<String>,
tags: Vec<String>,
}
fn main() {
// initialize the vector that will store the objects
// with the scraped quotes
let mut quotes: Vec<Quote> = Vec::new();
// the URL of the first page to scrape
let mut url = "https://quotes.toscrape.com/".to_owned();
loop {
// download the HTML document associated with the target page
let response = reqwest::blocking::get(url);
// extract the raw HTML from the response
let html = response.unwrap().text().unwrap();
// parse the HTML content
let document = scraper::Html::parse_document(&html);
// select all quote HTML elements on the page
let html_quote_selector = scraper::Selector::parse(".quote").unwrap();
let html_quotes = document.select(&html_quote_selector);
// iterate over each HTML quote to extract data
for html_quote in html_quotes {
// data scraping logic
let quote_selector = scraper::Selector::parse(".text").unwrap();
let quote = html_quote
.select("e_selector)
.next()
.map(|element| element.text().collect::<String>());
let author_selector = scraper::Selector::parse(".author").unwrap();
let author = html_quote
.select(&author_selector)
.next()
.map(|element| element.text().collect::<String>());
let tags_selector = scraper::Selector::parse(".tag").unwrap();
let tags = html_quote
.select(&tags_selector)
.map(|element| element.text().collect::<String>())
.collect();
// create a new quote object with the scraped data
// and store it in the list
let quote_obj = Quote {
quote,
author,
tags,
};
quotes.push(quote_obj);
}
// select the "Next ->" element
let next_page_element_selector = scraper::Selector::parse(".next").unwrap();
let next_page_element = document.select(&next_page_element_selector).next();
// if this is not the last page
if next_page_element.is_some() {
// retrieve the relative URL to the next page
let next_page_link_selector = scraper::Selector::parse("a").unwrap();
let partial_url = next_page_element
.unwrap()
.select(&next_page_link_selector)
.next()
.and_then(|a| a.value().attr("href"))
.map(str::to_owned)
.unwrap();
// the next page to scrape
url = format!("https://quotes.toscrape.com{partial_url}");
} else {
break;
}
}
// initialize the CSV output file
let path = std::path::Path::new("quotes.csv");
let mut writer = csv::Writer::from_path(path).unwrap();
// append the header to the CSV
writer.write_record(&["quote", "author", "tags"]).unwrap();
// populate the CSV file
for quote_obj in quotes {
// if the "quote" and "author" fields are not None
if let (Some(quote), Some(author)) = (quote_obj.quote, quote_obj.author) {
let tags = quote_obj.tags.join("; ");
writer.write_record(&[quote, author, tags]).unwrap();
}
}
// free up the writer resources
writer.flush().unwrap();
}
Amazing! In around 100 lines of code, you can build a data scraper in Rust!
Compile the application with:
cargo build
Then, run it with:
cargo run
Be patient while the Rust scraper retrieves data from each page. When it terminates, a quotes.csv file will appear in the root folder of your project. Open it and you should see the following data:
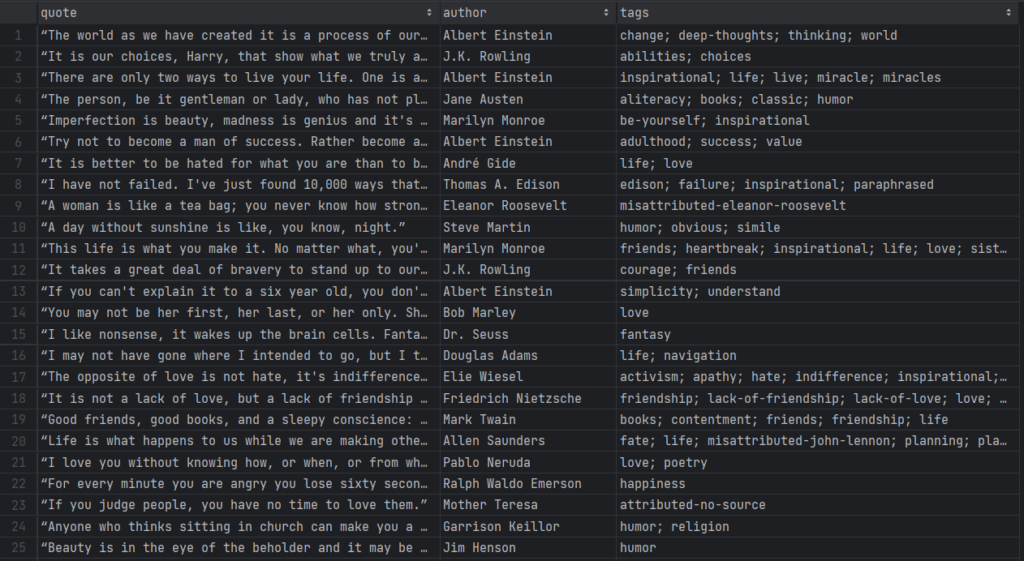
Et voilà! You started from unstructured data in online pages and now have it in a handy CSV file!
Conclusion
In this guide, you saw why Rust is an efficient language for web scraping. You also had the opportunity to explore some of its best scraping libraries. Then, you learned how to use them to create a Rust scraper that can extract data from a real-world target. As you saw, web scraping with Rust is simple and takes only a few lines of code.
The main issue is represented by the anti-bot and anti-scraping systems websites adopt to protect their data. These solutions can detect and block your scraping script. Fortunately, Bright Data has a set of solutions for you:
- Web Scraper IDE: A cloud IDE to build web scrapers that can automatically bypass and avoid any blocks.
- Scraping Browser: A cloud-based controllable browser that offers JavaScript rendering capabilities while handling CAPTCHAs, browser fingerprinting, automated retries, and more for you. It integrates with the most popular automation browser libraries, such as Playwright and Puppeteer.
- Web Unlocker: An unlocking API that can seamlessly return the raw HTML of any page, circumventing any anti-scraping measures.
Don’t want to deal with web scraping at all but are still interested in online data? Explore Bright Data’s ready-to-use datasets!





