Are you interested in scraping Pinterest, and you are looking for the best scraping bot for doing that, or are you looking to develop your own custom Pinterest scraper? Then you are on the right page as we would be providing you recommendations on the best Pinterest scrapers and how to develop custom ones if you are a coder.

The image-sharing social media platform that helps you discover ideas and information is quite popular among Internet users, especially if searches involve visual searches. Pinterest has proven itself to be a leader in the image sharing niche, and this can be confirmed with its over 400 million active users. Just like every top website online, Pinterest is home to a large dataset that is only identifiable by the skilled eye.
If Pinterest posts and pins interest you and you want to collect these, then this article has been written for you. In this article, we would be showing you what scraping Pinterest means, how a Pinterest scraper can be developed, and the best already-made Pinterest scrapers in the market.
Our focus is on the use of scraper because it is not possible and even if it is, manually extracting data from Pinterest is inefficient, time-wasting, and error-prone. On the other hand, Pinterest does not provide an API for collecting data from the platform. So we are left with scraping the data we want.
One thing you need to know is that scraping Pinterest sounds easy in concept, but because of its anti-spam system, it is not quite easy to get that done. Let take a look at an overview of what scraping Pinterest entails.
Pinterest Scraping – an Overview
The whole idea behind web scraping Pinterest is using a computer bot known as a web scraper to collect data from interest from Pinterest, which could either be with textual or visual data. Web scraping is arguably the fastest way to collect data from websites that do not offer a data API.
Since Pinterest does not offer an API, we have no choice but to make use of a web scraper to collect data of interest. However, you need to know that Pinterest does not allow the use of web scrapers and other programs that access it in an automated fashion. While it does not support scraping, it does not mean doing so is illegal, provided the data is publicly available.
The main issue would be in what you use scraped data for since a large chunk of visual data on Pinterest is copyrighted. Another problem you will have to face is resistance from Pinterest as you try to scrape data from its platform. Pinterest, just like every other top service, Has an anti-spam system that discourages scraping and would block you if it discovers you are trying to scrape its content.
Pinterest tracks you using your IP address and the cookie it drops in your browser. Cookie tracking is not much of a problem since you can either decide to save a cookie or not. For IP tracking, you will need to make use of proxies. Depending on the scale you want to scrape, you might also need to guard against Captchas.
How to Scrape Pinterest Using Python and Selenium

If you are not a coder, you should go to the net section, where you will find recommendations on the already-made web scraper you can use to scrape Pinterest even without coding knowledge. For this section, we would be showing coders how to utilize their coding skills to develop a custom Pinterest scraper.
If you have decided to scrape Pinterest, then the number one thing you need to do is to check whether you can access the data with JavaScript OFF. This would determine the libraries or framework you will use. We tried turning OFF JavaScript execution and got an error stating that Pinterest works only when JavaScript execution is allowed.
For Python, if you need to scrape a JavaScript-depending website like Pinterest, you will need to use Selenium as opposed to the duo of Requests and BeautifulSoup since Requests does not render JavaScript. Selenium automates your browser, and as such, you can use it to open the Python page, which would then render the content of the page then use the API provided by Selenium to access the data you are interested in collecting.
Selenium has support for Chrome, Firefox, and PhantomJS. To learn how to use Selenium for Python programming, read the official Selenium Python doc here. Below is an example of a Pinterest scraper for scraping Pinterest. I don’t code this – you can find the code on GitHub here.
from selenium import webdriver
from selenium.common.exceptionsimport StaleElementReferenceException
from selenium.webdriver.common.keysimport Keys
import time, random, socket, unicodedata
import string, copy, os
import pandas as pd
import requests
try:
from urlparseimport urlparse
except ImportError:
from six.moves.urllib.parseimport urlparse
defdownload(myinput, mydir="./"):
if isinstance(myinput, str) or isinstance(myinput, bytes):
# http://automatetheboringstuff.com/chapter11/
res = requests.get(myinput)
res.raise_for_status()
# https://stackoverflow.com/questions/18727347/how-to-extract-a-filename-from-a-url-append-a-word-to-it
outfile = mydir + "/" + os.path.basename(urlparse(myinput).path)
playFile = open(outfile, 'wb')
for chunk in res.iter_content(100000):
playFile.write(chunk)
playFile.close()
elifisinstance(myinput, list):
for i in myinput:
download(i, mydir)
else:
pass
defphantom_noimages():
from fake_useragentimport UserAgent
from selenium.webdriver.common.desired_capabilitiesimport DesiredCapabilities
ua = UserAgent()
# ua.update()
# https://stackoverflow.com/questions/29916054/change-user-agent-for-selenium-driver
caps = DesiredCapabilities.PHANTOMJS
caps["phantomjs.page.settings.userAgent"] = ua.random
return webdriver.PhantomJS(service_args=["--load-images=no"], desired_capabilities=caps)
defranddelay(a, b):
time.sleep(random.uniform(a, b))
defu_to_s(uni):
return unicodedata.normalize('NFKD', uni).encode('ascii', 'ignore')
class Pinterest_Helper(object):
def__init__(self, login, pw, browser=None):
if browser is None:
# http://tarunlalwani.com/post/selenium-disable-image-loading-different-browsers/
profile = webdriver.FirefoxProfile()
profile.set_preference("permissions.default.image", 2)
self.browser = webdriver.Firefox(firefox_profile=profile)
else:
self.browser = browser
self.browser.get("https://www.pinterest.com")
emailElem = self.browser.find_element_by_name('id')
emailElem.send_keys(login)
passwordElem = self.browser.find_element_by_name('password')
passwordElem.send_keys(pw)
passwordElem.send_keys(Keys.RETURN)
randdelay(2, 4)
defgetURLs(self, urlcsv, threshold=500):
tmp = self.read(urlcsv)
results = []
for t in tmp:
tmp3 = self.runme(t, threshold)
results = list(set(results + tmp3))
random.shuffle(results)
return results
defwrite(self, myfile, mylist):
tmp = pd.DataFrame(mylist)
tmp.to_csv(myfile, index=False, header=False)
defread(self, myfile):
tmp = pd.read_csv(myfile, header=None).values.tolist()
tmp2 = []
for i in range(0, len(tmp)):
tmp2.append(tmp[i][0])
return tmp2
defrunme(self, url, threshold=500, persistence=120, debug=False):
final_results = []
previmages = []
tries = 0
try:
self.browser.get(url)
while threshold >0:
try:
results = []
images = self.browser.find_elements_by_tag_name("img")
if images == previmages:
tries += 1
else:
tries = 0
if tries > persistence:
if debug == True:
print("Exitting: persistence exceeded")
return final_results
for i in images:
src = i.get_attribute("src")
if src:
if src.find("/236x/") != -1:
src = src.replace("/236x/", "/736x/")
results.append(u_to_s(src))
previmages = copy.copy(images)
final_results = list(set(final_results + results))
dummy = self.browser.find_element_by_tag_name('a')
dummy.send_keys(Keys.PAGE_DOWN)
randdelay(1, 2)
threshold -= 1
except (StaleElementReferenceException):
if debug == True:
print("StaleElementReferenceException")
threshold -= 1
except (socket.error, socket.timeout):
if debug == True:
print("Socket Error")
except KeyboardInterrupt:
return final_results
if debug == True:
print("Exitting at end")
return final_results
defrunme_alt(self, url, threshold=500, tol=10, minwait=1, maxwait=2, debug=False):
final_results = []
heights = []
dwait = 0
try:
self.browser.get(url)
while threshold >0:
try:
results = []
images = self.browser.find_elements_by_tag_name("img")
cur_height = self.browser.execute_script("return document.documentElement.scrollTop")
page_height = self.browser.execute_script("return document.body.scrollHeight")
heights.append(int(page_height))
if debug == True:
print("Current Height: " + str(cur_height))
print("Page Height: " + str(page_height))
if len(heights) >tol:
if heights[-tol:] == [heights[-1]] * tol:
if debug == True:
print("No more elements")
return final_results
else:
if debug == True:
print("Min element: {}".format(str(min(heights[-tol:]))))
print("Max element: {}".format(str(max(heights[-tol:]))))
for i in images:
src = i.get_attribute("src")
if src:
if src.find("/236x/") != -1:
src = src.replace("/236x/", "/736x/")
results.append(u_to_s(src))
final_results = list(set(final_results + results))
self.browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
randdelay(minwait, maxwait)
threshold -= 1
except (StaleElementReferenceException):
if debug == True:
print("StaleElementReferenceException")
threshold -= 1
except (socket.error, socket.timeout):
if debug == True:
print("Socket Error. Waiting {} seconds.".format(str(dwait)))
time.sleep(dwait)
dwait += 1
# except (socket.error, socket.timeout):
# if debug == True:
# print("Socket Error")
except KeyboardInterrupt:
return final_results
if debug == True:
print("Exitting at end")
return final_results
defscrape_old(self, url):
results = []
self.browser.get(url)
images = self.browser.find_elements_by_tag_name("img")
for i in images:
src = i.get_attribute("src")
if src:
if string.find(src, "/236x/") != -1:
src = string.replace(src, "/236x/", "/736x/")
results.append(u_to_s(src))
return results
defclose(self):
self.browser.close()
- How to extract follower profiles, posts, hashtags, from Instagram
- How to scrape Facebook groups post with python
- How to Scrape TikTok Using Python and Selenium
Best Pinterest Scrapers in the Market
In this section, we would be recommending web scrapers you can use to scrape Pinterest without you reinventing the wheel. Most of the scrapers that would be discussed below do not require you towrite a single line of code and do not even require you to have such knowledge in other to make use of it.
Pinterest Data Collector
![]()
- Pricing: Starts at $500 for 151K page loads
- Free Trials: Available
- Data Output Format: Excel
- Supported Platforms: Web-based
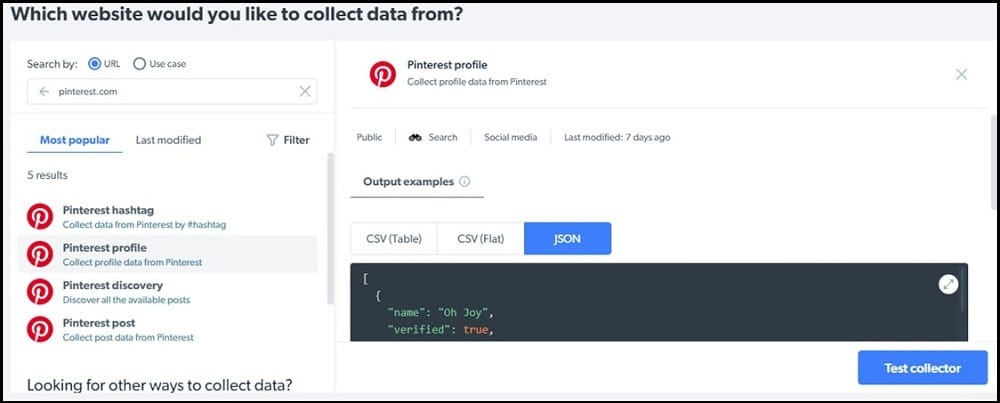
The Data Collector service is owned and managed by Bright Data, a leader in the proxy market. The Data Collector service has a group of scrapers you can use to scrape social media and e-commerce platforms.
It has got support for Pinterest and has a number of collectors for Pinterest. With this service, you cannot only scrape images; you can also collect posts by hashtag. It also has support for scraping Pinterest profiles and also helps in the discovery of posts, among other tasks.
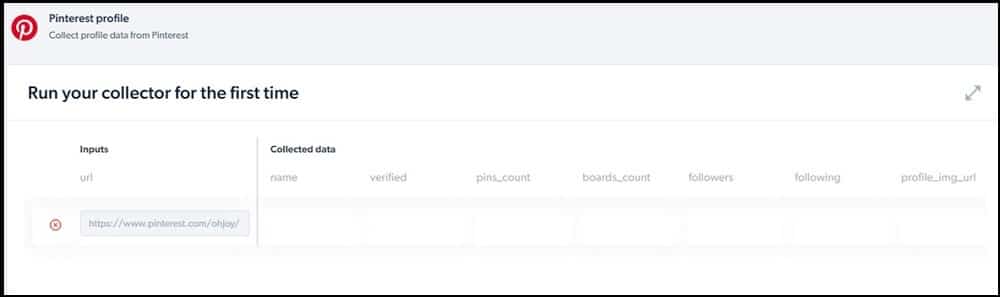
This service is available as a web-based tool, and you do not need any coding skills to use it. Pricing is based on page load, but you will need to add funds to your account to start using it.
Octoparse
![]()
- Pricing: Starts at $75 per month
- Free Trials: 14 days of free trial with limitations
- Data Output Format: CSV, Excel, JSON, MySQL, SQLServer
- Supported Platform: Cloud, Desktop
If you are looking forward to scraping images and other visual content from Pinterest, then Octoparse is the tool for you. Octoparse will not only scrape visual content; it does have support for other content, including textual content. What makes this tool so powerful is the fact that it has been built for the modern web and integrates anti-block techniques to help you get content you are interested in without any hassle.
Octoparse has proven to be one of the best web scrapers you can use for scraping Pinterest. However, it is not a Pinterest-only tool; you can use it to scrape data from any other website, and just like in the case of Data Collector, it does not require you to have coding skills.
ScrapeStorm
![]()
- Pricing: Starts at $49.99 per month
- Free Trials: Starter plan is free – comes with limitations
- Data Output Format: TXT, CSV, Excel, JSON, MySQL, Google Sheets, etc.
- Supported Platforms: Desktop, Cloud
ScrapeStorm is another web scraper that you can use to scrape Pinterest as a non-coder. This tool is a visual scraping tool that provides you a point and clicks interface for identifying data you are interested in. the tool also has support for scraping images and other types of visuals.
One feature you will come to like about ScrapeStorm not necessarily related to Pinterest scraping is its support for automatic data of interest identification, which makes the use of manual operation unnecessary – thanks to the fact that the web scraper is an Artificial Intelligence (AI) based scraping tool. This tool has the best data output support format when compared to the other tools mentioned.
ParseHub
![]()
- Pricing: Free with a paid plan
- Free Trials: Free – advance features come at an extra cost
- Data Output Format: Excel, JSON,
- Supported Platform: Cloud, Desktop
ParseHub is a general web scraping tool that you can use to scrape data from any website you want. The tool has been developed for the modern web and, as such, can be used for scraping JavaScript-dependent websites such as Pinterest. You can use it to scrape the content of a whole board.
One thing you will come to like about this tool is that it has a free tier that you can use if you do not have a budget for scraping. However, the true power of ParseHub reveals itself when you pay for it as it allows you access to its cloud-based platform and also offers you other advanced features, including file retention for storage.
WebScraper.io Extension

- Pricing: Freemium
- Free Trials: Freemium
- Data Output Format: CSV, XLSX, and JSON
- Supported Platform: Browser extension (Chrome and Firefox)

WebScraper.io is another service that can help you scrape Pinterest content. The service offers a Chrome extension and Firefox add-on, which you can use to scrape Pinterest straight from your browser without using any other native tool.
The extensions are free to use, and you can use them to scrape any website you want to as they have the capability to scrape data from all kinds of pages. One thing you will come to like about this service is that it is quite easy to use and offers you a point and click interface for scraping any data you want from a page. It also comes with modular selector support.
Conclusion
Pinterest has carved a niche for itself in the social media space and is the best at what it does. If you find content on it appealing, then scraping them is the option for you. Interestingly, doing so is easy if you know the right tool for the job.
We have provided for you above a list of web scrapers you can use to scrape content from Pinterest. It is important you use proxies if the tool you choose requires such, and we recommend you use residential proxies from either Bright Data or Smartproxy.