Are you looking for a way to collect data from websites? This can be done with or without coding. The article below highlights how to get that done with a focus on using Python and a no-code scraping tool.

The Internet is one of the most important sources of data for researchers, businesses, and governmental organizations. With over 2.5 quintillion bytes of data generated every day on the Internet, data is no longer a problem for most businesses. The major problem is how to collect the data and what to do with the data. In this article, our focus is on helping you collect data while you sort out what you need the data for from your end.
Usually, when collecting data from websites is mentioned at this point, we expect you have your mind on automation. This is because you can’t possibly collect any reasonable amount of data at scale without automating the process. In the past, you need coding skills to successfully collect data from the web.
However, things have changed and there is also the option of doing so without writing a single line of code using no-code scraping tools. Both methods will be discussed below.
Web Scraping: The Method for Automated Web Data Collection
From the introduction, I mentioned that web data extraction is done in an automated manner right? Well, the process is known as web scraping. Web scraping is the process of using specialized web bots known as web scrapers to collect web data automatedly.
The process can be used for collecting data from the web at scale provided the location of the data point is known or the data has a pattern that can be used to identify it. While the method is quite helpful and fast, it is important you know that websites do not support it.
As a coder, you can develop custom code to specifically collect important data points from a website. However, if you are not a coder, you can use no-code scraping tools. These tools have been developed for web scraping without the need to write a single line of code.
Some provide you with a point-and-click interface as in the case of visual web scrapers while others will have a specialized interface for scraping specific websites.
What Type of Data Can Be Collected Online from Websites

It is important you know that all kinds of data available on the Internet can be scraped including text, images, videos, and even audio files. Below are some of the data that are scraped from the Internet the most.
-
Product Data
Product data such as product name, price, rating, specifications, and their associated customer reviews are some of the most scraped data from the Internet today. You can scrap product detail from e-commerce stores such as Amazon, Walmart, eBay, AliExpress, and a host of millions of other e-commerce stores online.
-
Lead Data
Emails, phone numbers, and names are some of the key details you need to speak to prospective customers and all of these are available at any scale online. LinkedIn is a popular source of lead data but it is not alone.
You can generate leads from Twitter, Facebook, and numerous online forums where users post their email addresses and phone number. Regular Express (Regex) is used a lot in this case.
-
User Opinions and Sentiments
As people are becoming open to discussing a lot of issues online, so there is a lot of data you can analyze on social issues. Many businesses, political bodies, and researchers scrape user-generated data on social media to find out user sentiments on a large scale. Facebook and Twitter are the most popular websites for scraping social user-generated content.
-
Other Generic Data
Government records, auto-generated data from sensors and IoT devices, data from research, and many more are also some of the most scraped data from the Internet. There are many more, some of which you might even find it difficult to classify them.
Just know that any publicly available data online can be scraped using a web scraper. The use case and importance of publicly available data are determined by those interested in the data.
How to Scrape Data From Websites Using Python

As stated earlier, there are two major types of web scraping tools — coders tools and non-coders tools. In this section, we will show you how to collect data from websites using the Python programming language. If you are a coder in another language, there is also abundant information on most languages on the web. Non-coders can skip this section to the section for using no-code scraping tools.
In other to collect data from websites using Python, you need basic Python coding skills and then learn how to make use of specific Python web scraping libraries. While you can use the modules in the Python standard library to scrape, you will find it difficult and as such, you are better off making use of third-party libraries. Let's take a look at some of these below.
Python Libraries for Web Scraping
Currently, the Python programming language has the best library support for web scraping — and there is always a tool for your web scraping need. Below are the 3 options available to you as a Python developer interested in web scraping.
-
Requests and BeautifulSoup
Requests is an HTTP library for sending web requests and getting back responses. This is used for downloading the HTML of web pages.
On the other hand, BeautifulSoup was built on a parser to make the extraction of data from HTML documents easy.
With these two, you can scrape regular HTML pages provided they do not depend on JavaScript rendering. If JavaScript execution and rendering are required, you will have to make use of another alternative.
-
Scrapy
Scrapy is basically a framework for web scraping and crawling. It is a more advanced tool and comes with most of the tools required for web scraping. It even does have support for middleware, making it a more robust solution. It is also faster than using Request and BeautifulSoup. However, it does not support JavaScript rendering tools and can be a little difficult to learn for beginners.
-
Selenium
Selenium is a web browser driver. What it does is that it automates web browsers and what you do with that is up to you. In our case, we use it to render pages as they appear to real users in other to scrape important data.
This is the popular tool for scraping data from pages that depend on Javascript for rendering its content. However, it can be slow and as such, you should only use it for scraping Javascript pages. For regular pages, use either of the two options above.
Problems Associated With Python Web Scraping
It is important to know that you will face a lot of issues with custom web scraper. This is because most websites do not like being scraped and have anti-scraping systems baked into their anti-spam system. You will need to avoid blocks by using rotating proxies to mask your IP address and exceed request limits set by websites.
For websites that use Captcha, you will need to make use of an anti-captcha. Also popular is the use of other techniques such as random delays between requests and setting/changing user agent and other relevant request headers.
However, aside from the issues of avoiding blocks, you also need to consider website structure change which is the reason most web scrapers need to be maintained. Most websites change their layout frequently and when they do, web scrapers used for scraping data off them will break since parsing is hard-coded.
Steps to Scraping Data Using Python With Example

Let me show you in practice, how to collect web data using Python. We will be using the Requests and BeautifulSoup libraries for doing this in this guide. As with all coding guides, a problem that needs to be solved is needed. For this example, we will develop a web scraper to collect product names and prices from Amazon product pages.
Step 1: Install Necessary Librariy
As stated earlier, we need to use third-party libraries to make things easier and the option we chose is the duo of Requests and BeautifulSoup. To install requests, run the command below in the command prompt.
“pip install requests”
To install BeautifulSoup, run the command below.
“pip install bs4”
It is expected you already have Python 3 installed before you run the commands above. If run successfully, you can go on with the next steps.
Step 2: Inspect the HTML of a Product Page to Identify Elements
Web pages are constructed using HTML and styled using CSS. The content you see on a page is enclosed in HTML elements. For you to extract data from a page, you need to know the element it is enclosed in and how to uniquely identify it.
You do this by viewing the source code. To view the source code, right-click and click on, “view source code.” Below is the screenshot highlighting the element with the product name.
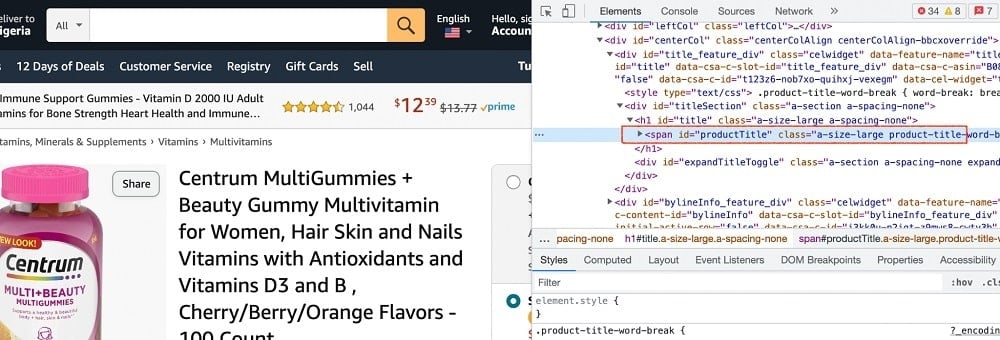
As you can see from the above, the product name is enclosed in a “span” element with the ID, productTitle. IDs for HTML elements are unique so we can use them as the CSS selector to get hold of the product name on Amazon. For the product price, below is the screenshot of its HTML element.
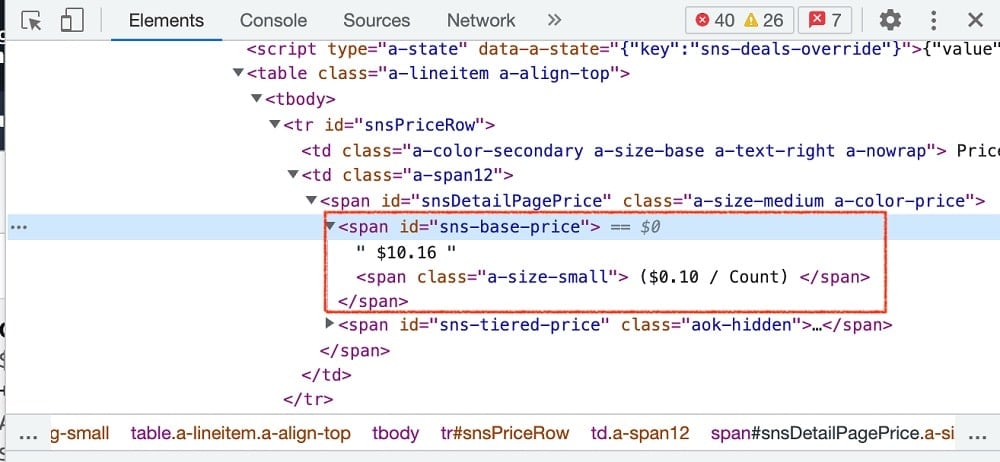
As you can see from the above, the price is enclosed also in a span element with the ID as sns-base-price. With this, we already got the CSS selectors required for our scraping as follows:
Product name: productTitle
Product price: sns-base-price
Step 3: Code Request Logic
Web scrapers basically request for HTML documents and then parse out required data from them. The first step is actually to request the HTML of a page and you use requests for doing that.
Below is a code that shows you how to request the product page using its URL. For this logic, we actually set a user-agent header to a regular as Amazon will block you if your user agent is suspicious.
import requests
from bs4 import BeautifulSoup
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
product_URL = "https://www.amazon.com/Centrum-Multigummies-Beauty-Gummy-Multivitamin/dp/B08YS6M82M/?_encoding=UTF8&pd_rd_w=nYgXc&content-id=amzn1.sym.6479f04b-39f5-47c1-9063-123e82e2ba82&pf_rd_p=6479f04b-39f5-47c1-9063-123e82e2ba82&pf_rd_r=261RCJHQ0G9Q7R63SBKZ&pd_rd_wg=1q9qj&pd_rd_r=f10dc5ca-aa97-4683-8fee-c564fd326a8f&ref_=pd_gw_trq_ed_dl30varo"
req = requests.get(product_URL, headers=HEADERS)
print(req.text)
Step 4: Create Soup and Extract Data

If you run the above code, you will see that it prints the HTML of the full page on the screen. But what we are after is not the raw HTML. We are after just the product name and price. For this, we use the BeautifulSoup tool to achieve that. Below is the code for that.
#extract product name
try:
product_title = soup.find("span", attrs={"id":'productTitle'}).text
except AttributeError:
product_title = ""
print(product_title)
#extract product price
try:
product_price = soup.find("span", attrs={'id':'sns-base-price'}).string.strip()
except AttributeError:
product_price = ""
print(product_price)
Step 5: Restructure Code
Below is the full code now structured in a class and methods.
import requests
from bs4 import BeautifulSoup
class ProductScraper:
def __init__(self, url):
self.product_URL = url
self.product_title = ""
self.product_price = ""
self.page_source = ""
def downlaod_page(self):
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
self.page_source = requests.get(self.product_URL, headers=HEADERS)
def get_product_title(self):
try:
product_title = self.page_source.find("span", attrs={"id": 'productTitle'}).text
except AttributeError:
product_title = ""
self.product_title = product_title
def get_product_price(self):
try:
product_price = self.page_source.find("span", attrs={'id': 'sns-base-price'}).string.strip()
except AttributeError:
product_price = ""
self.product_price = product_price
url = "https://www.amazon.com/Centrum-Multigummies-Beauty-Gummy-Multivitamin/dp/B08YS6M82M/?_encoding=UTF8&pd_rd_w=nYgXc&content-id=amzn1.sym.6479f04b-39f5-47c1-9063-123e82e2ba82&pf_rd_p=6479f04b-39f5-47c1-9063-123e82e2ba82&pf_rd_r=261RCJHQ0G9Q7R63SBKZ&pd_rd_wg=1q9qj&pd_rd_r=f10dc5ca-aa97-4683-8fee-c564fd326a8f&ref_=pd_gw_trq_ed_dl30varo"
c = ProductScraper(url)
c.downlaod_page()
c.get_product_title()
c.get_product_price()
print(c.product_title)
print(c.product_price)
How to Scrape Using No-code Scraping Tools
The above method is meant for non-coders. In the past, you will find it difficult to collect data from websites via web scraping if you are not a coder. This is no longer the case as there are no-code tools you can use without writing a single line of code.
And yes, these no-code tools work perfectly. There are many no-code scrapings in the market including Octoparse, ParseHub, ScrapeStorm, WebHarvy, and Helium Scraper.
In this guide, I will show you how to make use of WebHarvy to collect web data without writing a single line of code. Turns out these no-code tools provide an easy-to-use point-and-click interface for identifying data of interest on a page.
They feature a web browser for accessing web pages and then a point-and-click interface for selecting data from the page. We will be scraping products from the search page of Amazon.
Step 1: Install WebHarvy for No-Code Scraping
The first thing to do is to install the WebHarvy scraper from the official WebHarvy website. It is a paid tool but there is support for a free trial which you can use for this guide. This web scraper is currently available for only Windows. After downloading it, you can install it, launch it and provide your authentication details to start using it.
Step 2: Configuration
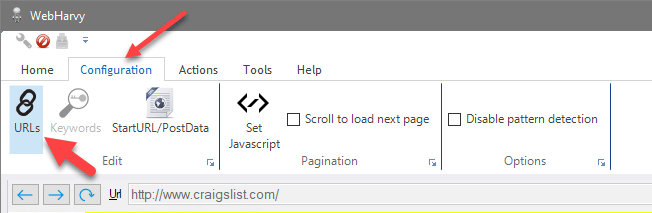
There is a configuration browser provided in the WebHarvy tool. Use this browser to visit Amazon and enter a search query. Once you are taken to the search page, stop there. That is where we will be scraping from. We will scrape the names of the products on the search page. For you to scrape these, you will need to make use of the point-and-click operation.
Click on the name of any of the products and an interface will come up. You will see different options such as capture text, capture URL, follow this URL, set as next page link, and more options. Click on capture text. Doing this will lead to the other products' names getting highlighted too.
Step 3: Start Scraping
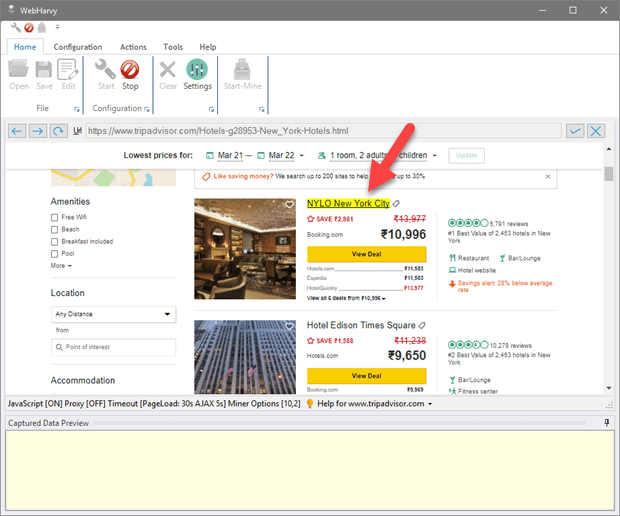
Once you are done capturing the required data, you can start scraping. To do that, click on the stop configuration button and start mining. This will collect the highlighted data in no time. You can save the scraped data as a file or export it to a database. It is important you know that this example has been simplified for easy understanding.
With WebHarvy, you can scrape images, follow links and even scrape from multiple pages via the pagination scraping option. As it stands today, the only major advantage of using a custom scraper is that you have better control and can integrate it as you like into your custom tool as well.
FAQs to collect data from website
Q. Is Collecting Data from Websites Allowed?
The act of collecting data via automated means is not allowed by most websites. This is either because of the overwhelming requests web scrapers send or because they do not want you to collect data from their platforms for free.
And for the popular websites out there, they have anti-scraping systems in place to make it difficult for you to collect data from their platform. Even with all of these, web scraping is still not illegal provided the data you scrape is publicly available to all users.
Q. What is the Best Method of Collecting Data from Websites?
Generally, you can already tell that web scraping is the best method for collecting data from websites. But what method of this is the best? The answer depends largely on your coding skills.
If you are a coder, you can simply develop a custom scraper, or use an already-made scraper to avoid reinventing the wheel and bypass headaches associated with web scraping. For non-coders, you can simply look outdoor no-code scraping tools as they are also perfect.
Conclusion
No doubt, the importance of data can not be overemphasized. And with the amount of data available on the Internet, there is no double that one will be interested in collecting them.
One thing you need to know is that using the right tool for web data extraction will go a long way. If you are finding it difficult to either develop one yourself or use a no-code scraping tool, you can simply make use of a professional data service that can help you get all of the data you need from the web.





