Is Akamai the anti-bot system blocking your bot? Until you learn how to bypass it, you won’t be able to carry out your automation tasks on websites protected by it. Below is an article on how to bypass Akamai.

Bot detectors such as Akamai may be able to tell which bot is good and which one is bad. This, amongst many other reasons, is why website owners have put this Content Delivery Network (CDN) in place to not only ensure the fast delivery of their content but also to wade off threats.
As a researcher who scrapes the Internet for various reasons, your actions, which may suggest that you are extracting data through the use of bots could get you blocked. Your intentions may be valid and genuine, but a bot detector does not know that.
The big question is how do you scale past this anti-bot detector while you carry out your scraping, or crawling, as the case may be? In this article, we have highlighted several actions you can take to bypass this sophisticated CDN and cybersecurity tool called Akamai. But before we begin to examine them one after the other, let's learn a little about Akamai and how it works.
What is Akamai?

Founded in 1998, Akamai Technology is a leading Content Delivery Network. It provides media and software delivery, cloud, and cybersecurity services for organisations. With operations in at least 135 countries in the world, Akamai has over 100 thousand servers all around the world, dedicated to delivering fast and high-quality content for organizations.
It helps secure the web and cloud operations of these organizations. It also serves as an Internet watchdog, constantly on the lookout for hackers, bad bots, and users who are restricted from getting access to the organization's website.
Aside from protecting organizations' websites from cyberattacks, it also accelerates content delivery to end users and optimizes the organization's upload time. It acts as the intermediary between the end user and the organization, reducing the gap of latency to its barest minimum.
Akamai optimizes web content for any kind of device, thereby providing smooth access to eligible users. What makes Akamai even better is that no additional hardware or software is required. It helps offload the existing infrastructure and scales even better.
Akamai is poised to solve the problem of clustering data due to the high volume of requests that may ensue when an organization has a large customer base. It achieves that by optimizing existing servers to speed up traffic and, at the same time, wading off any threat there might exist.
How does Akamai Work?

Have you wondered why some websites are slow to process requests? That's because they have not adopted the Akamai technology! Without the Akamai technology, when a customer tries to access a website that accepts customers from all around the world, for instance, they get frustrated by the website's latency.
This is because the customer's request has to pass through many countries to deliver to the company's server. The long and tiring process is the reason for the delay. And this way, Big businesses lose a lot of customers and money.
A company's server without Akamai can only process a specific number of requests. When this request exceeds its limit, it slows down its efficiency, which is safe to say is bad for big businesses. Akamai has over 100,000 (one hundred thousand) servers across the globe. This means that there is an Akamai server closest to the customer. So anytime they send a request, their devices communicate with the nearest Akamai server to them.
In turn, that server connects to the Akamai server closest to their target website, obtains information, and sends it back to the customers in a few seconds. Asides from being faster than the conventional way, it also caches and optimizes requests such as videos for any device anywhere. And oh, it is secured too.
Normally, in a DDoS (Distributed Denial of Service) attack, a company's server is hit by many threats from hackers and other malicious Internet criminals. This causes their server to break down. But with Akamai, the company's server cannot be hit because the numerous Akamai servers across the globe will take the hit instead.
The few affected Akamai servers may be down, but the rest unaffected ones will take over until the affected ones are back up. This way, the company's server remains untouched and safe. Consequently, the company gets good reviews from happy customers and makes more money.
How to Bypass Akamai
Some Internet activities require the use of bots to send multiple requests at an incredible speed beyond what humans can do. This could lead to the blocking of a user's access to a website by the website's pre-programmed anti-bot detection mechanism, also known as a Web Application Firewall (WAF).
This may not be directly intended for individuals who use these bots for various genuine purposes such as research, academic, comparison etc. But it may be difficult for a website's anti-bot systems to differentiate between good and bad bots. For research, academic, comparison, and other clear reasons for scraping or crawling, we shall be examining the various ways to bypass Akamai below.
1. Respect Robots.txt

Robots.txt files are a set of rules or instructions for bots. Many websites have their set of rules for bots, but since it is not linked anywhere on the website, you can't possibly come across it to assess. While you can't access it, your bots can.
It first attempts to read the laid down instructions and adhere to them if it is a good bot, such as a web crawler. Otherwise, it'll either ignore the instructions or, at best, process it to find out the web pages that are forbidden.
Websites expect that a good bot will not ignore these robots.txt rules. Therefore, it has no punishment for such bots. But a bad bot, due to its attempt to disregard these rules, will get itself banned, thereby halting your scraping.
For a website that adopts Akamai, it takes only a few seconds to get you blocked if it discovers that you have flagrantly disregarded its rules by scraping contents blocked by robot.txt. So, to be on the safer side, ensure you avoid crawling pages that robots.txt forbids.
2. Get Quality Rotating Proxies

Without proxies, when you scrape a website, your IP is visible, and you are just one second away from getting blocked if you cross the red line. Crossing the red line here means going against the website rule. If you send multiple requests using that same IP, you will get yourself blocked.
To avoid this, you need to get many different IP addresses, and that's where proxies come in.
Proxies help you disguise your Internet identity, leaving you anonymous while you scrape your data. In addition to that, some proxies have a rotating feature. That is, while sending requests, they automatically change your IP address within a specified time. The consistent changing of IPs makes it difficult for websites to detect or block you.
So, to beat Akamai, you need to get a good rotating proxy. There are quite a handful of them in the market, but residential proxies are more reliable if you are going to be sending a huge number of requests. They tend to be a bit more expensive than datacenter proxies and are not as fast as datacenter because they are physical devices. But you are assured of safety as they will keep you away from Akamai's detection and rotate your proxies as frequently as you want.
- Brightdata Proxy Network – Editor's choice
- Soax mobile Proxy Network – Most Stable choice
- Smartproxy residential proxy – Budget Choice
3. Use Headless Browsers

Headless browsers are browsers that do not have a Graphical User Interface (GUI). Unlike regular browsers, they do not have buttons or icons you can interact with. Headless browsers are usually executed via the command line or network communication.
Amongst its numerous uses is scraping public data.
However, there might be a little problem though. Websites understand that real web browsers can block Javascript. The simplest way for them to detect a headless browser is to check if the Web browser can render a Javascript block. If it can't, then the visit is marked as a bot.
To scale through this problem, you have to use some libraries that automatically control stuck browsers, such as Selenium Puppeteer and Playwright.
4. Pay Attention to HTTP Headers
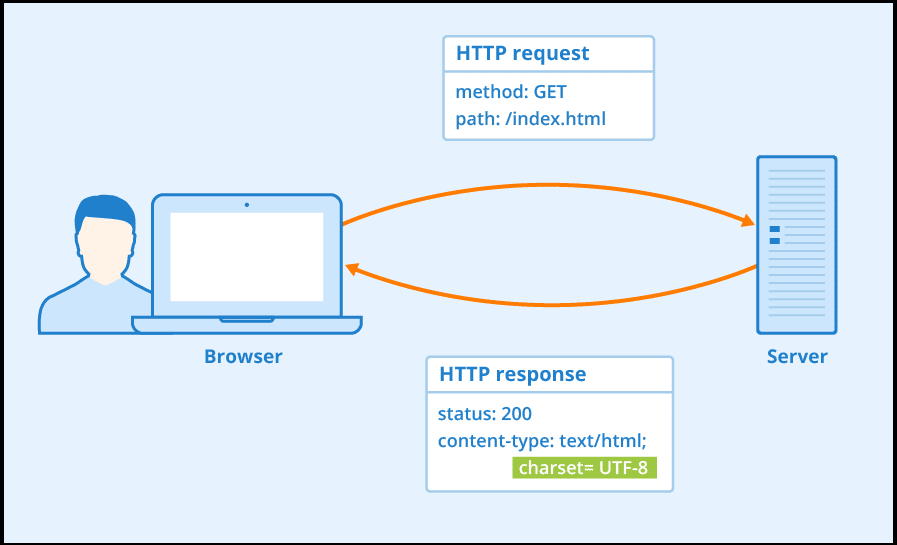
Browsers send a set of HTTP headers by default when you make a request. Websites can analyze your identity through these headers. To make you appear like. Human, just copy and paste them into your header object inside your code. This will make it look like you are sending requests from a real browser, thereby fooling Akamai into thinking that it is a real browser.
Be meticulous when changing them. Ensure that you change only the least you need. Ensure that the whole set makes sense. Akamai will sense that something is wrong if you add the same header for Chrome and other browsers.
Let's talk about Referrers. They are HTTP requests that let the website know where you are coming from. Ideally, you use Google as your referrer so that it will look like you are coming from Google. This is so because most websites generate traffic from Google, therefore, Akamai will not suspect foul play.
If you want to make Google your referrer, you can write your header like this: referrer:https://Google.com/
If you send a request without using Google as your referrer, chrome will send sec-fetch-site:none but if you set Google as your referrer, the browser will send sec-fetch-site:cross-site
You can check out common referrers for any websites using a tool like similarweb. Most times, this will be a divisor media site like Twitter or LinkedIn.
5. Use Stealth Mode for Headless Browsers
Anti-scraping tools are becoming smarter by the day and can tell if a browser is being controlled through library automation. That's a more advanced method than just checking if your browser can block Javascript or not.
Bot detection tools can tell if the browser is being controlled by automated libraries if:
- There are any specific signatures of bots.
- The browser supports non-standard features
- Presence of popular libraries such as Selenium, Puppeteer and Playwright.
- Human-induced movements such as mouse movements, clicks, scrolls, and tabs activities.
All the above come together and sends a message to the bot detector that the client is a bot or human.
Reliable ways to bypass this detection and avoid getting banned is getting these plugins:
- Puppeteer Extra – Puppeteer Stealth plugin
- Fingerprint rotation – Microsoft paper on fingerprint rotation.
Keep in mind that these automation libraries could be detected regardless, as websites are now upping their detection game by improving their Artificial Intelligence models. Therefore it is not 100% reliable. Adding a proxy to it is an excellent idea as it further guarantees you seamless crawling—or scraping, as the case may be. Asides from helping you disguise, the frequent rotation of IPs buys you some time and ensures you scrape successfully.
You maybe like to read,
- How to Manage a Couple Stealth Accounts?
- How to Create Multiple Stealth Facebook Ad Accounts
- How to Create a Stealth PayPal Accounts
6. Rotate User Agent and Corresponding HTTP Headers

A user agent is a tool that sends a message to the web server about what type of web browser you are using to access the website. Without this user agent in place, websites will deny you access to their content. To know your user agent, you can do a quick Google search with the keywords “What is my user agent?”
When you use the same user agent over and over again, the website's Akamai systems will detect you as a bot and get you blocked. To evade this detection and block, you might have to set your user agents to a fake one. You have to repeat the same after a while, just so your user agent doesn't begin to look like a bot to Akamai.
You can source user agents from what is my browser developers. They have loads of user agents for all kinds of browser software, operating systems, operating platforms, software types, hardware types, and layout engines.
Rotating your user agent is good, but it can only help you escape the basic Akamai detection and block. If your bots keep getting blocked even after using a new user agent, then you should consider adding some more HTTP headers.
7. Change your Crawling Pattern
It is very unlike humans to engage in only Internet activity repeatedly. Humans are known to be engaged in various activities when browsing around. The same cannot be said about bots. Bots are designed to perform a particular task, and it does that over and over again and quickly too.
Until it is redesigned to carry another specific task, it keeps doing what it was assigned to do. This repeated pattern of activity makes it very easy for Akamai to spot it and kick it out of the company's website in a matter of seconds.
Once in a while, incorporate random clicks on the website page. A few random clicks here and there will make the bots appear like humans, and so it becomes quite challenging for Akamai to detect it as a bot.
8. Be Careful with Honeypots

Think of a honeypot as a rodent trap with a carefully placed nice rodent meal to trick the rodent into eating the meal and getting its tail severed. In the world of computer security systems, a honeypot works similarly. It mimics the target for hackers, tricking them into clicking and thus submitting their details to the system. Honeypot looks like a real computer system, with applications and data, tricking unsuspecting hackers into thinking it is the real target.
It detects the actions of hackers through their modus operandi and thus gets to know their real intentions. Most times, it is used by websites to know where to tighten up their security architecture. For instance, a honeypot might have ports that respond to a port scan or weak passwords. Vulnerable ports might be exposed to fool hackers into the honeypot environment rather than the real and secured network.
Akamai moves swiftly to detect and block crawlers who have fallen prey to the spiders honeypot (a type of honeypot designed for web crawlers). Although honeypots cannot be seen by you, web scrapers can see them. On your part, steer clear of invisible links as much as you can. Even though they are not intended for you as a genuine scraper, it does not stop your bot from being blocked if detected.
9. Use CAPTCHA Solving Services

When you scrape websites on a large scale and too rapidly without any sign that you are human, you will be intercepted by Akamai. This is so because, from the indication of your actions, you could be using a bot which is against most websites' terms. This will make CAPTCHAS confront you to confirm if you are human or not.
In this case, it is best to use CAPTCHA-solving services to solve this problem. This tool helps you solve captcha problems through OCR (Optical Character Recognition). This method helps solve the captcha automatically. CAPTCHA-solving services are relatively cheap and are a handful when you are scraping in large.
Below are some reliable captcha-solving tools:
a) EndCaptcha – This captcha-solving service provider has the fastest captcha-solving speed in the market. They have a high accuracy rate and a high dedication to case-sensitive captchas.
b) Captcha Snipers – Captcha Snipers are very fast and accurate in solving captcha problems. It slashes your cost so you don't have to pay much to get their services.
c) 2Captcha – This captcha-solving service has 15 seconds for solving the normal captcha and 50 seconds for solving JS captcha.
10. Beware of Website Layout Change

One challenge you may face when scrapping is a change in page layout. Periodically, websites update their content to improve the experience of their users or to add new features. This could lead to some layout changes on the website.
Web scrapers are set up to scrape specific pages. If these pages change or are altered, they will find it hard to scrape such pages or not work at all. In this case, you will have to adjust your scraper.
Check how the layout is different from the rest of the pages and introduce a condition to your code to scrape those pages differently. Sometimes, even a minor change could require you to reconfigure your scraper.
11. Do Not Pressurise the Server During Crawling
If there's one thing that Akamai can detect you quickly with and deduce that you are using a bot, it is the speed at which you fetch data. Bots are known to extract data at a speed that no human can match. This action triggers Akamai or other anti-bot detective mechanisms; therefore, you will be blocked before you know it.
Asides from that, you are heading to get yourself blocked using bots (without proxies), and you are giving the website's server a lot of work to do. Thus, sending numerous requests could lead to its momentary breakdown.
To avert this problem, you might want to program your scraping tool to take a break in between data scraping. This will make it appear like a human and might be lucky to escape Akamai's wrath. And too it will prevent the site from going down. Scrape the smallest number of pages at a time by making the concurrent request. Ideally, put a break time of 10 – 20 seconds in between scraping.
FAQs Abut Bypass Akamai
Q. How Can I Tell if a Site Uses Akamai Technology?
Before you even think of a way to bypass Akamai, you need to be sure that the website you intend to scrape data from uses the Akamai technology or not. There are 3 specified methods of confirming this, we shall zero in on 2.
Step 1: Login to the Akamai control centre
Step 2: Select Your Services >> Support >> Diagnostic tools >> Debug URL
Step 3: Enter the URL of the website, including the protocol (e.g., https://example.com)
Step 4: If the URL resolves to an IP (as shown on the red line in the image below), when using Debug tool, then the site uses Akamai.
Step 5: If the result shows URL: Given URL/Hostname not akamized (as down in the red highlight in the image below), then the site does not use Akamai.
Q. How Much of the Internet uses Akamai?
Over half of Fortune 500 companies rely on Akamai to ensure the smooth running of their services. In addition to that, 225 game publishers, 200 national government agencies, and social media platforms across the globe.
In all, the company says that 85% of Internet users are on one single step on a network away from Content Delivery Network (CDN) run by Akamai. What makes Akamai stand out is that they have servers built in strategic places all over the world.
However, during covid, when work practices took a different turn, the increase in usage dug into the buffer Akamai likes to keep around its CDNs.
Q. Is Akamai GDPR Compliant?
Akamai has been in full compliance with the GDPR and other data protection regulations in the countries where they operate. When they make life better for billions of people billions of times per day, it is only expected that they protect the lives of these people online as all The commitment, they say, is fundamental to the trust that their customers have in them. Akamai continually analyses new legal regulations and adapts accordingly to maintain compliance.
Akamai does not collect, access, or store customer data rather than what is required to deliver and secure the traffic. Maintaining their customers' trust and confidence remains their utmost priority.
Conclusion
No doubt, escaping anti-bot systems detection is a complex conversation. Regardless, you should pay attention to details to avoid making mistakes and getting yourself banned before you even begin. Remember to abide by robots.txt rules. And do not scrape in large quantities. Program your scraping tool to pause in between extraction once in a while.
Akamai might be very effective and active, but it can still be tricked. Using proxies all along is one sure way to aid the bypassing. We hope that you have learned a thing or two about Akamai and how to bypass its watchful eyes.





