Do you want to avoid getting blocked while scraping data from the web or carrying out other tasks using Python? Then you are on the right page, as the article below discusses the key methods of avoiding blocks in Python.
Web automation makes our tasks on the Internet easier. Some tasks are even impossible to carry out without web automation, especially when required at a large scale.
Even with the importance of web automation to the web, web automation, in general, is hated by most web services. No website wants automation access — not for scraping its data or making purchases in an automated manner.
If you engage in web scraping or other forms of automation, you will agree with me that blocks are normal, except you take conscious steps to avoid them. Fortunately for us, you can actually avoid getting blocked.
If you are a Python developer looking to avoid getting blocked with Python, this article has been written for you. It is important you know that you need to put some things into consideration and use some technics into play to successfully avoid getting blocked as websites are becoming smarter at detecting bot-related activities.
One thing you need to know for sure is that if you know how a website detects bot activities, you can bypass the checks and make your bot look human as possible.
8 Proven Tips to Avoid Getting Blocked with Python
Python is just one of the programming languages used to develop web scrapers. However, it is actually one of the popular languages for bot development in general. Even if you are not a Python developer, the methods described here can be applied to your programming language of choice. Below are some of the ways you can avoid getting blocked with Python.
1: Use Rotating Proxies
The most elementary method of avoiding blocks when carrying out automation on the web is by using proxies. Proxies are basically intermediary servers that provide you with alternative IP addresses.
For their rotating counterparts, you are not just provided with one IP address — the IP address assigned to you is frequently changed. Frequent change of IP address is quite important if you must avoid getting blocked.
It turns out that each website has a request limit permit per IP address. If you try sending more requests from the same IP address, you will most likely get blocked. This request limit is not made known to the public and varies depending on the website and task.
But one thing we know that is certain — frequent changes of IP will help you avoid blocks due to sending too many requests from one IP address. Bots, by nature, send too many requests within a short period of time, and they need rotating proxies to scale through anti-spam systems of websites.
We recommend you make use of a high-quality residential proxy network with automatic IP rotation support. Bright Data and Smartproxy are some of the top recommended residential proxy networks with huge IP pools, good location support, and are quite undetectable.
- BrightData (Luminati Proxy) – Best Proxy Overall <Experts' #1 for Scraping>
- Smartproxy – Fast Residential Proxy pool <Best Value Choice>
- Soax – Best Mobile Proxy pool <Cleanest for Instagram automation>
For some tasks, residential proxies will not work — you will need mobile proxies. You can purchase rotating mobile proxies from Bright Data too. Soax is another provider of rotating mobile proxies that work. Using proxies in Python code is simple. Below is a sample code using the third-party request library.
import requests
proxies = {
'http': 'http://proxy.example.com:8080',
'https': 'http://secureproxy.example.com:8090',
}
url = 'http://mywebsite.com/example'
response = requests.post(url, proxies=proxies)
2: Use Captcha Solver
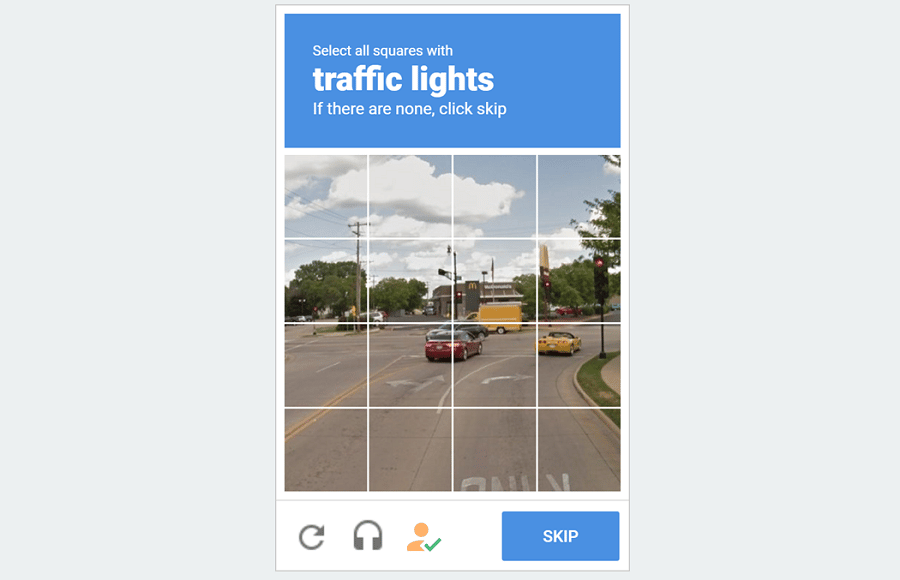
Websites are increasingly becoming smarter by the day, and just using proxies is not enough. Even with proxies, they can make a guess whether you are a bot or not. Some of the popular forms of blocks you will experience as a bot developer are Captchas.
And when you are hit with one, unless you are able to solve it, your task will end for that moment. How to deal with this is simple — make use of a captcha solver. With Captcha solvers, you are able to solve captcha the captchas that appear, thereby allowing you to continue your automation task without hindrance.
When it comes to solving captchas, there are many captcha-solving services in the market. 2Captcha and DeathByCaptcha are some of the popular options available to you. While some of the captchas can be solved via AI, most of the captchas nowadays require humans, and as such, these captcha solvers empty human captcha solvers from third-world countries to help solve captchas.
For this reason, do not expect to get free captcha solvers that work, especially when dealing with complex captchas that can’t be solved by using AI.
3: Set Custom User Agents and Other Relevant Headers —- and Rotate Them

One of the easiest way web services detect bots is by their user agents and other relevant headers. Python is a popular programming language for web scraping, and websites know the default headers set by Python and its popular HTTP libraries.
Take, for instance, the requests library use “python-requests/2.25” as the default user agent string. This will give you right away. In the past, I tried scraping Amazon without setting a custom user agent header using Python, and I was blocked. After setting the user agent to that of my Chrome browser, the request went through.
The user agent is meant to identify the client. Since websites only allow regular users, you are better off using the user agent of popular browsers. Here is a web page you can find details of user agents of popular web browsers. It is also important you know that aside from the user agent, there are also other relevant headers you need to set.
This differs depending on the websites. Use the Network tools in the Developer Tools of your browser to check the necessary headers set by your browser when sending a request to your website of target.
Some of the popular request headers include “Accept”, “Accept-Encoding”, and “Accept-Language.” The request headers that are unique and a must for your target website will be revealed to you if you use the developer tool. Just setting user agent is not enough. You also need to rotate the user agent. Below is a code on how to set the user agent string in Python.
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"}
response = requests.get("http://www.kite.com", headers=headers)
4: Use a Headless Browser

Another method you can use to avoid getting blocked is by using headless browsers. Headless browsers are software that acts like real browsers but without the browser User Interface (UI). They are mostly used for automated testing and web automation in general.
In the past, the only reason why you would need to make use of headless browsers for web scraping or other forms of automation was if the website of target depends on JavaScript to render its content. In the current times, websites use JavaScript to collect various data, which it uses for generating browser fingerprints or simple monitor behavior.
If you use regular HTTP libraries like the requests HTTP library for Python, your website of target can tell you are using a bot and not a browser. For Python developers, Selenium is the tool for the job. Selenium automates web browsers so that your bot that acts like a real browser.
It could trigger events just as clicks, scrolls, and all kinds of events. This will even reduce the occurrence of captchas because of how real your activities will be. The only major issue associated with using Selenium or any other tool for automating browsers is that it is slower compared to using regular HTTP libraries.
5: Set Random Delays Between Requests
One of the reasons why you get blocked easily is that your bot is sending too many web requests within a short period of time. If you are logged into an account on a website, then just know that proxies will not help you — you are known. Instead of trying to use proxies, you can as well throttle the speed at which you send requests.
As stated earlier, most websites will block you if you surpass their request limit. The only major way to deal with this is by setting delays in your code. For python, you can use the “sleep” method in the “time” class to set delays between requests. Aside from seeing delays, you are also better off making the delays random, as sending requests at the same intervals will also give you out as a bot.
6: Avoid Honeypots

Websites are becoming sneaky with their anti-scraping techniques. One of the ways they detect web scrapers is by setting honeytraps. Honeytraps are basically adding invisible links to a page. The link is disguised so that regular Internet users will not see them.
The link will have either its CSS attribute for display to none {display:none} or visibility to hidden {visibility:hidden}. With these attribute values, the links aren’t visible to the eyes, but automated bots will see them. Once there is a visit to such a URL, the website will block further requests.
Sometimes, they can get even smarter. Instead of using any of the aforementioned attributes, they will just set the URL cooler to white if the cooler of the background is white. This way, web scrapers looking to avoid URLs with their display or visibility value set to make them invisible will still get trapped.
For this reason, you should get all URLs to be crawled programmatically and make sure it does not have attributes or CSS settings that will make them hidden. Anyone detected should be avoided to avoid getting detected and blocked.
7: Scrape Google Cache Instead

Sometimes, your target site might just be a difficult nut to crack. If you do not want to deal with the hassles of trying to avoid getting blocked, you can scrape from the Google index.
Fortunately for us, Google keeps a cache of the pages available in its index. And the good news is it is not as protected as the Google Search platform itself. You can scrap from this index and save yourself the headache of dealing with anti-spam systems. To scrap from the Google cache, use this URL: “http://webcache.googleusercontent.com/search?q=cache:YOUR_URL“. Replace the YOUR_URL with the URL of your target page.
However, it is important you know that not all pages are available in Google Cache. Any webpage not available on Google, such as password-protected pages, can’t be found in Google Cache.
Also important is the fact that some websites, even though available on Google, stop Google from caching their pages for public access. The issue of freshness is also something to consider. If the data on a page changes often, the Google cache is useless in this case — and for unpopular websites, this is even worse because of the long delays between crawls.
8: Use Scraping APIs

The last resort for you to avoid getting blocked is using a scraping API. Scraping APIs are REST APIs that help you extract data from websites without you dealing with the issues of blocks. Most scraping APIs handle proxy management, headless browsers, and captchas. Some even come with parsers to make the extraction of data points easier for you.
And one good thing with scraping APIs is that you only get to pay for successful requests — this makes them strive more to deliver, as that is only when they make money. With scraping APIs, you only get to focus on data and not blocks.
It also helps you avoid worrying about managing web scrapers and website changes. Currently, ScraperAPI, ScrapingBee, and WebScraperAPI are the best scraping APIs out there. They are also affordable too.
Conclusion
The methods described above are some of the best methods you can use to avoid getting blocked when automating your tasks in Python. One good thing about the methods described above is that they are not unique to Python.
The methods to avoid getting blocked when carrying out web scraping or other forms of automation is not unique to any programming language. You can apply them in other languages as well.





